Dynamic random-access memory
| Computer memory types |
|---|
| Volatile |
| RAM |
| In development |
| Historical |
|
| Non-volatile |
| ROM |
| NVRAM |
| Early stage NVRAM |
| Mechanical |
| In development |
| Historical |
|

Dynamic random-access memory (DRAM) is a type of random-access memory that stores each bit of data in a separate capacitor within an integrated circuit. The capacitor can be either charged or discharged; these two states are taken to represent the two values of a bit, conventionally called 0 and 1. Since even "nonconducting" transistors always leak a small amount, the capacitors will slowly discharge, and the information eventually fades unless the capacitor charge is refreshed periodically. Because of this refresh requirement, it is a dynamic memory as opposed to static random-access memory (SRAM) and other static types of memory. Unlike flash memory, DRAM is volatile memory (vs. non-volatile memory), since it loses its data quickly when power is removed. However, DRAM does exhibit limited data remanence.
DRAM is widely used in digital electronics where low-cost and high-capacity memory is required. One of the largest applications for DRAM is the main memory (colloquially called the "RAM") in modern computers; and as the main memories of components used in these computers such as graphics cards (where the "main memory" is called the graphics memory). In contrast, SRAM, which is faster and more expensive than DRAM, is typically used where speed is of greater concern than cost, such as the cache memories in processors.
The advantage of DRAM is its structural simplicity: only one transistor and a capacitor are required per bit, compared to four or six transistors in SRAM. This allows DRAM to reach very high densities. The transistors and capacitors used are extremely small; billions can fit on a single memory chip. Due to the dynamic nature of its memory cells, DRAM consumes relatively large amounts of power, with different ways for managing the power consumption.[2]
History
The cryptanalytic machine code-named "Aquarius" used at Bletchley Park during World War II incorporated a hard-wired dynamic memory. Paper tape was read and the characters on it "were remembered in a dynamic store. ... The store used a large bank of capacitors, which were either charged or not, a charged capacitor representing cross (1) and an uncharged capacitor dot (0). Since the charge gradually leaked away, a periodic pulse was applied to top up those still charged (hence the term 'dynamic')".[3]
In 1964, Arnold Farber and Eugene Schlig, working for IBM, created a hard-wired memory cell, using a transistor gate and tunnel diode latch. They replaced the latch with two transistors and two resistors, a configuration that became known as the Farber-Schlig cell. In 1965, Benjamin Agusta and his team at IBM created a 16-bit silicon memory chip based on the Farber-Schlig cell, with 80 transistors, 64 resistors, and 4 diodes. In 1966, DRAM was invented by Dr. Robert Dennard at the IBM Thomas J. Watson Research Center. He was granted U.S. patent number 3,387,286 in 1968. Capacitors had been used for earlier memory schemes such as the drum of the Atanasoff–Berry Computer, the Williams tube and the Selectron tube.
The Toshiba "Toscal" BC-1411 electronic calculator, which was introduced in November 1966,[4] used a form of DRAM built from discrete components.[5]
In 1969 Honeywell asked Intel to make a DRAM using a three-transistor cell that they had developed. This became the Intel 1102[6] in early 1970. However, the 1102 had many problems, prompting Intel to begin work on their own improved design, in secrecy to avoid conflict with Honeywell. This became the first commercially available DRAM, the Intel 1103, in October 1970, despite initial problems with low yield until the fifth revision of the masks. The 1103 was designed by Joel Karp and laid out by Pat Earhart. The masks were cut by Barbara Maness and Judy Garcia.[7]
The first DRAM with multiplexed row and column address lines was the Mostek MK4096 4 Kbit DRAM designed by Robert Proebsting and introduced in 1973. This addressing scheme uses the same address pins to receive the low half and the high half of the address of the memory cell being referenced, switching between the two halves on alternating bus cycles. This was a radical advance, effectively halving the number of address lines required, which enabled it to fit into packages with fewer pins, a cost advantage that grew with every jump in memory size. The MK4096 proved to be a very robust design for customer applications. At the 16 Kbit density, the cost advantage increased; the 16 Kbit Mostek MK4116 DRAM, introduced in 1976, achieved greater than 75% worldwide DRAM market share. However, as density increased to 64 Kbit in the early 1980s, Mostek and other US manufacturers was overtaken by Japanese DRAM manufacturers selling higher-quality DRAMs using the same multiplexing scheme.
Principles of operation
.png)
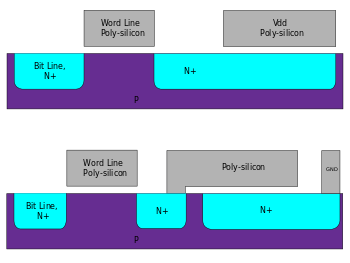
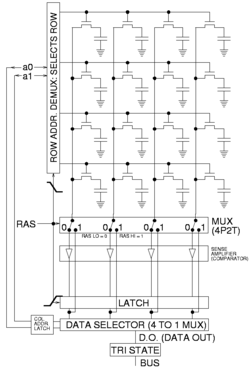
DRAM is usually arranged in a rectangular array of charge storage cells consisting of one capacitor and transistor per data bit. The figure to the right shows a simple example with a four-by-four cell matrix. Some DRAM matrices are many thousands of cells in height and width.[8][9]
The long horizontal lines connecting each row are known as word-lines. Each column of cells is composed of two bit-lines, each connected to every other storage cell in the column (the illustration to the right does not include this important detail). They are generally known as the "+" and "−" bit lines.
Operations to read a data bit from a DRAM storage cell
- The sense amplifiers are disconnected.[10]
- The bit-lines are precharged to exactly equal voltages that are in between high and low logic levels (e.g., 0.5 V if the two levels are 0 and 1 V). The bit-lines are physically symmetrical to keep the capacitance equal, and therefore at this time their voltages are equal.[10]
- The precharge circuit is switched off. Because the bit-lines are relatively long, they have enough capacitance to maintain the precharged voltage for a brief time. This is an example of dynamic logic.[10]
- The desired row's word-line is then driven high to connect a cell's storage capacitor to its bit-line. This causes the transistor to conduct, transferring charge from the storage cell to the connected bit-line (if the stored value is 1) or from the connected bit-line to the storage cell (if the stored value is 0). Since the capacitance of the bit-line is typically much higher than the capacitance of the storage cell, the voltage on the bit-line increases very slightly if the storage cell's capacitor is discharged and decreases very slightly if the storage cell is charged (e.g., 0.54 and 0.45 V in the two cases). As the other bit-line holds 0.50 V there is a small voltage difference between the two twisted bit-lines.[10]
- The sense amplifiers are now connected to the bit-lines pairs. Positive feedback then occurs from the cross-connected inverters, thereby amplifying the small voltage difference between the odd and even row bit-lines of a particular column until one bit line is fully at the lowest voltage and the other is at the maximum high voltage. Once this has happened, the row is "open" (the desired cell data is available).[10]
- All storage cells in the open row are sensed simultaneously, and the sense amplifier outputs latched. A column address then selects which latch bit to connect to the external data bus. Reads of different columns in the same row can be performed without a row opening delay because, for the open row, all data has already been sensed and latched.[10]
- While reading of columns in an open row is occurring, current is flowing back up the bit-lines from the output of the sense amplifiers and recharging the storage cells. This reinforces (i.e. "refreshes") the charge in the storage cell by increasing the voltage in the storage capacitor if it was charged to begin with, or by keeping it discharged if it was empty. Note that due to the length of the bit-lines there is a fairly long propagation delay for the charge to be transferred back to the cell's capacitor. This takes significant time past the end of sense amplification, and thus overlaps with one or more column reads.[10]
- When done with reading all the columns in the current open row, the word-line is switched off to disconnect the storage cell capacitors (the row is "closed") from the bit-lines. The sense amplifier is switched off, and the bit-lines are precharged again.[10]
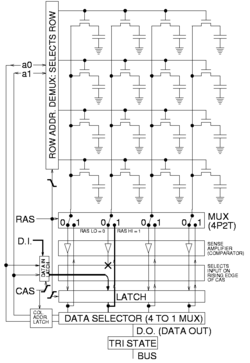
To write to memory
To store data, a row is opened and a given column's sense amplifier is temporarily forced to the desired high or low voltage state, thus causing the bit-line to charge or discharge the cell storage capacitor to the desired value. Due to the sense amplifier's positive feedback configuration, it will hold a bit-line at stable voltage even after the forcing voltage is removed. During a write to a particular cell, all the columns in a row are sensed simultaneously just as during reading, so although only a single column's storage-cell capacitor charge is changed, the entire row is refreshed (written back in), as illustrated in the figure to the right.[10]
Refresh rate
Typically, manufacturers specify that each row must be refreshed every 64 ms or less, as defined by the JEDEC standard.
Some systems refresh every row in a burst of activity involving all rows every 64 ms. Other systems refresh one row at a time staggered throughout the 64 ms interval. For example, a system with 213 = 8,192 rows would require a staggered refresh rate of one row every 7.8 µs which is 64 ms divided by 8,192 rows. A few real-time systems refresh a portion of memory at a time determined by an external timer function that governs the operation of the rest of a system, such as the vertical blanking interval that occurs every 10–20 ms in video equipment.
The row address of the row that will be refreshed next is maintained by external logic or a counter within the DRAM. A system that provides the row address (and the refresh command) does so to have greater control over when to refresh and which row to refresh. This is done to minimize conflicts with memory accesses, since such a system has both knowledge of the memory access patterns and the refresh requirements of the DRAM. When the row address is supplied by a counter within the DRAM, the system relinquishes control over which row is refreshed and only provides the refresh command. Some modern DRAMs are capable of self-refresh; no external logic is required to instruct the DRAM to refresh or to provide a row address.
Under some conditions, most of the data in DRAM can be recovered even if the DRAM has not been refreshed for several minutes.[11]
Memory timing
Many parameters are required to fully describe the timing of DRAM operation. Here are some examples for two timing grades of asynchronous DRAM, from a data sheet published in 1998:[12]
| "50 ns" | "60 ns" | Description | |
|---|---|---|---|
| tRC | 84 ns | 104 ns | Random read or write cycle time (from one full /RAS cycle to another) |
| tRAC | 50 ns | 60 ns | Access time: /RAS low to valid data out |
| tRCD | 11 ns | 14 ns | /RAS low to /CAS low time |
| tRAS | 50 ns | 60 ns | /RAS pulse width (minimum /RAS low time) |
| tRP | 30 ns | 40 ns | /RAS precharge time (minimum /RAS high time) |
| tPC | 20 ns | 25 ns | Page-mode read or write cycle time (/CAS to /CAS) |
| tAA | 25 ns | 30 ns | Access time: Column address valid to valid data out (includes address setup time before /CAS low) |
| tCAC | 13 ns | 15 ns | Access time: /CAS low to valid data out |
| tCAS | 8 ns | 10 ns | /CAS low pulse width minimum |
Thus, the generally quoted number is the /RAS access time. This is the time to read a random bit from a precharged DRAM array. The time to read additional bits from an open page is much less.
When such a RAM is accessed by clocked logic, the times are generally rounded up to the nearest clock cycle. For example, when accessed by a 100 MHz state machine (i.e. a 10 ns clock), the 50 ns DRAM can perform the first read in five clock cycles, and additional reads within the same page every two clock cycles. This was generally described as "5‐2‐2‐2" timing, as bursts of four reads within a page were common.
When describing synchronous memory, timing is described by clock cycle counts separated by hyphens. These numbers represent tCL‐tRCD‐tRP‐tRAS in multiples of the DRAM clock cycle time. Note that this is half of the data transfer rate when double data rate signaling is used. JEDEC standard PC3200 timing is 3‐4‐4‐8[13] with a 200 MHz clock, while premium-priced high performance PC3200 DDR DRAM DIMM might be operated at 2‐2‐2‐5 timing.[14]
| PC-3200 (DDR-400) | PC2-6400 (DDR2-800) | PC3-12800 (DDR3-1600) | Description | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Typical | Fast | Typical | Fast | Typical | Fast | ||||||||
| cycles | time | cycles | time | cycles | time | cycles | time | cycles | time | cycles | time | ||
| tCL | 3 | 15 ns | 2 | 10 ns | 5 | 12.5 ns | 4 | 10 ns | 9 | 11.25 ns | 8 | 10 ns | /CAS low to valid data out (equivalent to tCAC) |
| tRCD | 4 | 20 ns | 2 | 10 ns | 5 | 12.5 ns | 4 | 10 ns | 9 | 11.25 ns | 8 | 10 ns | /RAS low to /CAS low time |
| tRP | 4 | 20 ns | 2 | 10 ns | 5 | 12.5 ns | 4 | 10 ns | 9 | 11.25 ns | 8 | 10 ns | /RAS precharge time (minimum precharge to active time) |
| tRAS | 8 | 40 ns | 5 | 25 ns | 16 | 40 ns | 12 | 30 ns | 27 | 33.75 ns | 24 | 30 ns | Row active time (minimum active to precharge time) |
...Minimum random access time has improved from tRAC = 50 ns to tRCD + tCL = 22.5 ns, and even the premium 20 ns variety is only 2.5 times better compared to the typical case (~2.22 times better). CAS latency has improved even less, from tCAC = 13 ns to 10 ns. However, the DDR3 memory does achieve 32 times higher bandwidth; due to internal pipelining and wide data paths, it can output two words every 1.25 ns (1600 Mword/s), while the EDO DRAM can output one word per tPC = 20 ns (50 Mword/s).
Timing abbreviations
|
|
DRAM cells
Each bit of data in a DRAM is stored as a positive or negative electrical charge in a capacitive structure. The structure providing the capacitance, as well as the transistors that control access to it, is collectively referred to as a DRAM cell. They are the fundamental building block in DRAM arrays. Multiple DRAM memory cell variants exist, but the most commonly used variant in modern DRAMs is the one-transistor, one-capacitor (1T1C) cell. The transistor is used to admit current into the capacitor during writes, and to discharge the capacitor during reads. The access transistor is designed to maximize drive strength and minimize transistor-transistor leakage (Kenner, pg. 34).
The capacitor has two terminals, one of which is connected to its access transistor, and the other to either ground or VCC/2. In modern DRAMs, the latter case is more common, since it allows faster operation. In modern DRAMs, a voltage of +VCC/2 across the capacitor is required to store a logic one; and a voltage of -VCC/2 across the capacitor is required to store a logic zero. The electrical charge stored in the capacitor is measured in coulombs. For a logic one, the charge is: , where Q is the charge in coulombs and C is the capacitance in farads. A logic zero has a charge of: .[15]


Reading or writing a logic one requires the wordline is driven to a voltage greater than the sum of VCC and the access transistor's threshold voltage (VTH). This voltage is called VCC pumped (VCCP). The time required to discharge a capacitor thus depends on what logic value is stored in the capacitor. A capacitor containing logic one begins to discharge when the voltage at the access transistor's gate terminal is above VCCP. If the capacitor contains a logic zero, it begins to discharge when the gate terminal voltage is above VTH.[16]
Capacitor design
Up until the mid-1980s, the capacitors in DRAM cells were co-planar with the access transistor (they were constructed on the surface of the substrate), thus they were referred to as planar capacitors. The drive to increase both density, and to a lesser extent, performance, required denser designs. This was strongly motivated by economics; a major consideration for DRAM devices, especially commodity DRAMs. The minimization of DRAM cell area can produce a denser device (which could be sold at a higher price), or a lower priced device with the same capacity. Starting in the mid-1980s, the capacitor has been moved above or below the silicon substrate in order to meet these objectives. DRAM cells featuring capacitors above the substrate are referred to as stacked or folded plate capacitors; whereas those with capacitors buried beneath the substrate surface are referred to as trench capacitors. In the 2000s, manufacturers were sharply divided by the type of capacitor used by their DRAMs, and the relative cost and long-term scalability of both designs has been the subject of extensive debate. The majority of DRAMs, from major manufactures such as Hynix, Micron Technology, Samsung Electronics use the stacked capacitor structure, whereas smaller manufacturers such Nanya Technology use the trench capacitor structure (Jacob, pp. 355–357).
The capacitor in the stacked capacitor scheme is constructed above the surface of the substrate. The capacitor is constructed from an oxide-nitride-oxide (ONO) dielectric sandwiched in between two layers of polysilicon plates (the top plate is shared by all DRAM cells in an IC), and its shape can be a rectangle, a cylinder, or some other more complex shape. There are two basic variations of the stacked capacitor, based on its location relative to the bitline—capacitor-over-bitline (COB) and capacitor-under-bitline (CUB). In a former variation, the capacitor is underneath the bitline, which is usually made of metal, and the bitline has a polysilicon contact that extends downwards to connect it to the access transistor's source terminal. In the latter variation, the capacitor is constructed above the bitline, which is almost always made of polysilicon, but is otherwise identical to the COB variation. The advantage the COB variant possesses is the ease of fabricating the contact between the bitline and the access transistor's source as it is physically close to the substrate surface. However, this requires the active area to be laid out at a 45-degree angle when viewed from above, which makes it difficult to ensure that the capacitor contact does not touch the bitline. CUB cells avoid this, but suffer from difficulties in inserting contacts in between bitlines, since the size of features this close to the surface are at or near the minimum feature size of the process technology (Kenner, pp. 33–42).
The trench capacitor is constructed by etching a deep hole into the silicon substrate. The substrate volume surrounding the hole is then heavily doped to produce a buried n+ plate and to reduce resistance. A layer of oxide-nitride-oxide dielectric is grown or deposited, and finally the hole is filled by depositing doped polysilicon, which forms the top plate of the capacitor. The top the capacitor is connected to the access transistor's drain terminal via a polysilicon strap (Kenner, pp. 42&ndash44). A trench capacitor's depth-to-width ratio in DRAMs of the mid-2000s can exceed 50:1 (Jacob, p. 357).
Trench capacitors have numerous advantages. Since the capacitor is buried in the bulk of the substrate instead of lying on its surface, the area it occupies can be minimized to what is required to connect it to the access transistor's drain terminal without decreasing the capacitor's size, and thus capacitance (Jacob, pp. 356–357). Alternatively, the capacitance can be increased by etching a deeper hole without any increase to surface area (Kenner, pg. 44). Another advantage of the trench capacitor is that its structure is under the layers of metal interconnect, allowing them to be more easily made planar, which enables it to be integrated in a logic-optimized process technology, which have many levels of interconnect above the substrate. The fact that the capacitor is under the logic means that it is constructed before the transistors are. This allows high-temperature processes to fabricate the capacitors, which would otherwise be degrading the logic transistors and their performance. This makes trench capacitors suitable for constructing embedded DRAM (eDRAM) (Jacob, p. 357). Disadvantages of trench capacitors are difficulties in reliably constructing the capacitor's structures within deep holes and in connecting the capacitor to the access transistor's drain terminal (Kenner, pg. 44).
Historical cell designs
First-generation DRAM ICs (those with capacities of 1 Kbit), of which the first was the Intel 1103, used a three-transistor, one-capacitor (3T1C) DRAM cell. By the second-generation, the requirement to increase density by fitting more bits in a given area, or the requirement to reduce cost by fitting the same amount of bits in a smaller area, lead to the almost universal adaptation of the 1T1C DRAM cell, although a couple of devices with 4 and 16 Kbit capacities continued to use the 3T1C cell for performance reasons (Kenner, p. 6). These performance advantages included, most significantly, the ability to read the state stored by the capacitor without discharging it, avoiding the need to write back what was read out (non-destructive read). A second performance advantage relates to the 3T1C cell has separate transistors for reading and writing; the memory controller can exploit this feature to perform atomic read-modify-writes, where a value is read, modified, and then written back as a single, indivisible operation (Jacob, p. 459).
Proposed cell designs
The drive to increase density and performance has led to the one-transistor, zero-capacitor (1T) DRAM cell being a topic of research since the late-1990s. In 1T DRAM cells, there is a transistor for controlling access to a capacitive region used to store the bit of data, but this capacitance is not provided by a separate capacitor. Instead, the parasitic body capacitor inherent in silicon-on-insulator (SOI) transistors is used instead. Subsequently, 1T DRAM cells have the greatest density, and can be easily integrated with logic since they are constructed from the same SOI process technologies used for high-performance logic. A key difference from 1T1C DRAMs is that reads in 1T DRAM are non-destructive; the stored charge causes a detectable shift in the threshold voltage of the transistor. Refresh, however, is still required.[17] Performance-wise, access times are significantly better than capacitor-based DRAMs, but slightly worse than SRAM. Examples of such DRAMs include A-RAM and Z-RAM.
DRAM array structures
DRAM cells are laid out in a regular rectangular, grid-like pattern to facilitate their control and access via wordlines and bitlines. The physical layout of the DRAM cells in an array is typically designed so that two adjacent DRAM cells in a column share a single bitline contact to reduce their area. DRAM cell area is given as n F2, where n is a number derived from the DRAM cell design, and F is the smallest feature size of a given process technology. This scheme permits comparison of DRAM size over different process technology generations, as DRAM cell area scales at linear or near-linear rates over. The typical area for modern DRAM cells varies between 6–8 F2.
The horizontal wire, the wordline, is connected to the gate terminal of every access transistor in its row. The vertical bitline is connected to the source terminal of the transistors in its a column. The lengths of the wordlines and bitlines are limited. The wordline length is limited by the desired performance of the array, since propagation time of the signal that must transverse the wordline is determined by the RC time constant. The bitline length is limited by its capacitance (which increases with length), which must be kept within a range for proper sensing (as DRAMs operate by sensing the charge of the capacitor released onto the bitline). Bitline length is also limited by the amount of operating current the DRAM can draw and by how power can be dissipated, since these two characteristics are largely determined by the charging and discharging of the bitline.
Bitline architecture
Sense amplifiers are required to read the state contained in the DRAM cells. When the access transistor is activated, the electrical charge in the capacitor is shared with the bitline. The bitline's capacitance is much greater than that of the capacitor (approximately ten times). Thus, the change in bitline voltage is minute. Sense amplifiers are required to resolve the voltage differential into the levels specified by the logic signaling system. Modern DRAMs use differential sense amplifiers, and are accompanied by requirements as to how the DRAM arrays are constructed. Differential sense amplifiers work by driving their outputs to opposing extremes based on the relative voltages on pairs of bitlines. The sense amplifiers function effectively and efficient only if the capacitance and voltages of these bitline pairs are closely matched. Besides ensuring that the lengths of the bitlines and the number of attached DRAM cells attached to them are equal, two basic architectures to array design have emerged to provide for the requirements of the sense amplifiers: open and folded bitline arrays.
Open bitline arrays
The first generation (1 Kbit) DRAM ICs, up until the 64 Kbit generation (and some 256 Kbit generation devices) had open bitline array architectures. In these architectures, the bitlines are divided into multiple segments, and the differential sense amplifiers are placed in between bitline segments. Because the sense amplifiers are placed between bitline segments, to route their outputs outside the array, an additional layer of interconnect placed above those used to construct the wordlines and bitlines is required.
The DRAM cells that are on the edges of the array do not have adjacent segments. Since the differential sense amplifiers require identical capacitance and bitline lengths from both segments, dummy bitline segments are provided. The advantage of the open bitline array is a smaller array area, although this advantage is slightly diminished by the dummy bitline segments. The disadvantage that caused the near disappearance of this architecture is the inherent vulnerability to noise, which affects the effectiveness of the differential sense amplifiers. Since each bitline segment does not have any spatial relationship to the other, it is likely that noise would affect only one of the two bitline segments.
Folded bitline arrays
The folded bitline array architecture routes bitlines in pairs throughout the array. The close proximity of the paired bitlines provide superior common-mode noise rejection characteristics over open bitline arrays. The folded bitline array architecture began appearing in DRAM ICs during the mid-1980s, beginning with the 256 Kbit generation. This architecture is favored in modern DRAM ICs for its superior noise immunity.
This architecture is referred to as folded because it takes its basis from the open array architecture from the perspective of the circuit schematic. The folded array architecture appears to remove DRAM cells in alternate pairs (because two DRAM cells share a single bitline contact) from a column, then move the DRAM cells from an adjacent column into the voids.
The location where the bitline twists occupies additional area. To minimize area overhead, engineers select the simplest and most area-minimal twisting scheme that is able to reduce noise under the specified limit. As process technology improves to reduce minimum feature sizes, the signal to noise problem worsens, since coupling between adjacent metal wires is inversely proportional to their pitch. The array folding and bitline twisting schemes that are used must increase in complexity in order to maintain sufficient noise reduction. Schemes that have desirable noise immunity characteristics for a minimal impact in area is the topic of current research (Kenner, p. 37).
Future array architectures
Advances in process technology could result in open bitline array architectures being favored if it is able to offer better long-term area efficiencies; since folded array architectures require increasingly complex folding schemes to match any advance in process technology. The relationship between process technology, array architecture, and area efficiency is an active area of research.
Row and column redundancy
The first DRAM ICs did not have any redundancy. An IC with a defective DRAM cell would be discarded. Beginning with the 64 Kbit generation, DRAM arrays have included spare rows and columns to improve yields. Spare rows and columns provide tolerance of minor fabrication defects which have caused a small number of rows or columns to be inoperable. The defective rows and columns are physically disconnected from the rest of the array by a triggering a programmable fuse or by cutting the wire by a laser. The spare rows or columns are substituted in by remapping logic in the row and column decoders (Jacob, pp. 358–361).
Embedded DRAM (eDRAM)
DRAM that is integrated into an integrated circuit designed in a logic-optimized process, such as an application-specific integrated circuit (ASIC) or a microprocessor, is called embedded DRAM (eDRAM). Embedded DRAM requires DRAM cell designs that can be fabricated without preventing the fabrication of fast-switching transistors used in high-performance logic, and modification of the basic logic-optimized process technology to accommodate the process steps required to build DRAM cell structures.
Error detection and correction
Electrical or magnetic interference inside a computer system can cause a single bit of DRAM to spontaneously flip to the opposite state. The majority of one-off ("soft") errors in DRAM chips occur as a result of background radiation, chiefly neutrons from cosmic ray secondaries, which may change the contents of one or more memory cells or interfere with the circuitry used to read/write them. Recent studies give widely varying error rates for single event upsets with over seven orders of magnitude difference, ranging from roughly one bit error, per hour, per gigabyte of memory to one bit error, per century, per gigabyte of memory.[18][19][20]
The problem can be mitigated by using redundant memory bits and additional circuitry that use these bits to detect and correct soft errors. In most cases, the detection and correction logic is performed by the memory controller; sometimes, the required logic is transparently implemented within DRAM chips or modules, enabling the ECC memory functionality for otherwise ECC-incapable systems.[21] The extra memory bits are used to record parity and to enable missing data to be reconstructed by error-correcting code (ECC). Parity allows the detection of all single-bit errors (actually, any odd number of wrong bits). The most common error-correcting code, a SECDED Hamming code, allows a single-bit error to be corrected and, in the usual configuration, with an extra parity bit, double-bit errors to be detected.
Recent studies give widely varying error rates with over seven orders of magnitude difference, ranging from 10−10−10−17 error/bit·h, roughly one bit error, per hour, per gigabyte of memory to one bit error, per century, per gigabyte of memory.[18][19][20] The Schroeder et al. 2009 study reported a 32% chance that a given computer in their study would suffer from at least one correctable error per year, and provided evidence that most such errors are intermittent hard rather than soft errors.[22] A 2010 study at the University of Rochester also gave evidence that a substantial fraction of memory errors are intermittent hard errors.[23] Large scale studies on non-ECC main memory in PCs and laptops suggest that undetected memory errors account for a substantial number of system failures: the study reported a 1-in-1700 chance per 1.5% of memory tested (extrapolating to an approximately 26% chance for total memory) that a computer would have a memory error every eight months.[24]
Security
Data remanence
Although dynamic memory is only specified and guaranteed to retain its contents when supplied with power and refreshed every short period of time (often 64 ms), the memory cell capacitors often retain their values for significantly longer, particularly at low temperatures.[25] Under some conditions most of the data in DRAM can be recovered even if it has not been refreshed for several minutes.[26]
This property can be used to circumvent security and recover data stored in the main memory that is assumed to be destroyed at power-down. The computer could be quickly rebooted, and the contents of the main memory read out; or by removing a computer's memory modules, cooling them to prolong data remanence, then transferring them to a different computer to be read out. Such an attack was demonstrated to circumvent popular disk encryption systems, such as the open source TrueCrypt, Microsoft's BitLocker Drive Encryption, and Apple's FileVault.[25] This type of attack against a computer is often called a cold boot attack.
Memory corruption
Dynamic memory, by definition, requires periodic refresh. Furthermore reading dynamic memory is a destructive operation, requiring a recharge of the storage cells in the row that has been read. If these processes are imperfect, a read operation can cause Soft error. In particular, there is a risk that some charge can leak between nearby cells, causing the refresh or read of one row to cause a disturbance error in an adjacent or even nearby row. The awareness of disturbance errors dates back the first commercially available DRAM in the early 1970s (the Intel 1103). Despite the mitigation techniques employed by manufacturers, commercial researchers proved in a 2014 analysis that commercially available DDR3 DRAM chips manufactured in 2012 and 2013 are susceptible to disturbance errors.[27] The associated side effect that led to observed bit flips has been dubbed row hammer.
Packaging
For economic reasons, the large (main) memories found in personal computers, workstations, and non-handheld game-consoles (such as PlayStation and Xbox) normally consist of dynamic RAM (DRAM). Other parts of the computer, such as cache memories and data buffers in hard disks, normally use static RAM (SRAM). However, since SRAM has high leakage power and low density, die-stacked DRAM has recently been used for designing multi-megabyte sized processor caches.[28]
Physically, most DRAM is packaged in black epoxy resin.
General DRAM formats



Dynamic random access memory is produced as integrated circuits (ICs) bonded and mounted into plastic packages with metal pins for connection to control signals and buses. In early use individual DRAM ICs were usually either installed directly to the motherboard or on ISA expansion cards; later they were assembled into multi-chip plug-in modules (DIMMs, SIMMs, etc.). Some standard module types are:
- DRAM chip (Integrated Circuit or IC)
- DRAM (memory) modules
- Single In-line Pin Package (SIPP)
- Single In-line Memory Module (SIMM)
- Dual In-line Memory Module (DIMM)
- Rambus In-line Memory Module (RIMM), technically DIMMs but called RIMMs due to their proprietary slot.
- Small outline DIMM (SO-DIMM), about half the size of regular DIMMs, are mostly used in notebooks, small footprint PCs (such as Mini-ITX motherboards), upgradable office printers and networking hardware like routers.
- Small outline RIMM (SO-RIMM). Smaller version of the RIMM, used in laptops. Technically SO-DIMMs but called SO-RIMMs due to their proprietary slot.
- Stacked vs. non-stacked RAM modules
- Stacked RAM modules contain two or more RAM chips stacked on top of each other. This allows large modules to be manufactured using cheaper low density wafers. Stacked chip modules draw more power, and tend to run hotter than non-stacked modules. Stacked modules can be packaged using the older TSOP or the newer BGA style IC chips. Silicon dies connected with older wire bonding or newer TSV.
- Several proposed stacked RAM approaches exist, with TSV and much wider interfaces, including Wide I/O, Wide I/O 2, Hybrid Memory Cube and High Bandwidth Memory.
Common DRAM modules
Common DRAM packages as illustrated to the right, from top to bottom (last three types are not present in the group picture, and the last type is available in a separate picture):
- DIP 16-pin (DRAM chip, usually pre-fast page mode DRAM (FPRAM))
- SIPP 30-pin (usually FPRAM)
- SIMM 30-pin (usually FPRAM)
- SIMM 72-pin (often extended data out DRAM (EDO DRAM) but FPRAM is not uncommon)
- DIMM 168-pin (most SDRAM but were some extended data out DRAM (EDO DRAM))
- DIMM 184-pin (DDR SDRAM)
- RIMM 184-pin (RDRAM)
- DIMM 240-pin (DDR2 SDRAM and DDR3 SDRAM)
- DIMM 288-pin (DDR4 SDRAM)
Common SO-DIMM DRAM modules:
- 72-pin (32-bit)
- 144-pin (64-bit) used for SO-DIMM SDRAM
- 200-pin (72-bit) used for SO-DIMM DDR SDRAM and SO-DIMM DDR2 SDRAM
- 204-pin (64-bit) used for SO-DIMM DDR3 SDRAM
- 260-pin used for SO-DIMM DDR4 SDRAM
Memory size of a DRAM module
The exact number of bytes in a DRAM module is always an integral power of two. A 512 MB (as marked on a module) SDRAM DIMM, actually contains 512 MiB (mebibytes) = 512 × 220 bytes = 229 bytes = 536,870,912 bytes exactly, and might be made of 8 or 9 SDRAM chips, each containing exactly 512 Mib (mebibits) of storage, and each one contributing 8 bits to the DIMM's 64- or 72-bit width. For comparison, a 2 GB SDRAM module contains 2 GiB (gibibytes) = 2 × 230 bytes = 231 bytes = 2,147,483,648 bytes of memory, exactly. The module usually has 8 SDRAM chips of 256 MiB each.
Versions
While the fundamental DRAM cell and array has maintained the same basic structure (and performance) for many years, there have been many different interfaces for communicating with DRAM chips. When one speaks about "DRAM types", one is generally referring to the interface that is used.
DRAM can be divided into asynchronous and synchronous DRAM. In addition, graphics DRAM is specially designed for graphics tasks, and can be asynchronous or synchronous DRAM in nature. Pseudostatic RAM (PSRAM) have an architecture and interface that closely mimics the operation and interface of static RAM. Lastly, 1T DRAM uses a capacitorless design, as opposed to the usual 1T/1C (one transistor/one capacitor) designs of conventional DRAM.
Asynchronous DRAM
Principles of operation
An asynchronous DRAM chip has power connections, some number of address inputs (typically 12), and a few (typically one or four) bidirectional data lines. There are four active-low control signals:
- RAS, the Row Address Strobe. The address inputs are captured on the falling edge of RAS, and select a row to open. The row is held open as long as RAS is low.
- CAS, the Column Address Strobe. The address inputs are captured on the falling edge of CAS, and select a column from the currently open row to read or write.
- WE, Write Enable. This signal determines whether a given falling edge of CAS is a read (if high) or write (if low). If low, the data inputs are also captured on the falling edge of CAS.
- OE, Output Enable. This is an additional signal that controls output to the data I/O pins. The data pins are driven by the DRAM chip if RAS and CAS are low, WE is high, and OE is low. In many applications, OE can be permanently connected low (output always enabled), but it can be useful when connecting multiple memory chips in parallel.
This interface provides direct control of internal timing. When RAS is driven low, a CAS cycle must not be attempted until the sense amplifiers have sensed the memory state, and RAS must not be returned high until the storage cells have been refreshed. When RAS is driven high, it must be held high long enough for precharging to complete.
Although the DRAM is asynchronous, the signals are typically generated by a clocked memory controller, which limits their timing to multiples of the controller's clock cycle.
RAS Only Refresh (ROR)
Classic asynchronous DRAM is refreshed by opening each row in turn.
The refresh cycles are distributed across the entire refresh interval in such a way that all rows are refreshed within the required interval. To refresh one row of the memory array using RAS Only Refresh, the following steps must occur:
- The row address of the row to be refreshed must be applied at the address input pins.
- RAS must switch from high to low. CAS must remain high.
- At the end of the required amount of time, RAS must return high.
This can be done by supplying a row address and pulsing RAS low; it is not necessary to perform any CAS cycles. An external counter is needed to iterate over the row addresses in turn.[29]
CAS before RAS refresh (CBR)
For convenience, the counter was quickly incorporated into the DRAM chips themselves. If the CAS line is driven low before RAS (normally an illegal operation), then the DRAM ignores the address inputs and uses an internal counter to select the row to open. This is known as CAS-before-RAS (CBR) refresh. This became the standard form of refresh for asynchronous DRAM, and is the only form generally used with SDRAM.
Hidden refresh
Given support of CAS-before-RAS refresh, it is possible to deassert RAS while holding CAS low to maintain data output. If RAS is then asserted again, this performs a CBR refresh cycle while the DRAM outputs remain valid. Because data output is not interrupted, this is known as hidden refresh.[30]
Page mode DRAM
Page mode DRAM is a minor modification to the first-generation DRAM IC interface which improved the performance of reads and writes to a row by avoiding the inefficiency of precharging and opening the same row repeatedly to access a different column. In Page mode DRAM, after a row was opened by holding RAS low, the row could be kept open, and multiple reads or writes could be performed to any of the columns in the row. Each column access was initiated by asserting CAS and presenting a column address. For reads, after a delay (tCAC), valid data would appear on the data out pins, which were held at high-Z before the appearance of valid data. For writes, the write enable signal and write data would be presented along with the column address.[31]
Page mode DRAM was later improved with a small modification which further reduced latency. DRAMs with this improvement were called fast page mode DRAMs (FPM DRAMs). In page mode DRAM, CAS was asserted before the column address was supplied. In FPM DRAM, the column address could be supplied while CAS was still deasserted. The column address propagated through the column address data path, but did not output data on the data pins until CAS was asserted. Prior to CAS being asserted, the data out pins were held at high-Z. FPM DRAM reduced tCAC latency.[32]
Static column is a variant of fast page mode in which the column address does not need to be stored in, but rather, the address inputs may be changed with CAS held low, and the data output will be updated accordingly a few nanoseconds later.[32]
Nibble mode is another variant in which four sequential locations within the row can be accessed with four consecutive pulses of CAS. The difference from normal page mode is that the address inputs are not used for the second through fourth CAS edges; they are generated internally starting with the address supplied for the first CAS edge.[32]
Extended data out DRAM (EDO DRAM)

EDO DRAM, sometimes referred to as Hyper Page Mode enabled DRAM, is similar to Fast Page Mode DRAM with the additional feature that a new access cycle can be started while keeping the data output of the previous cycle active. This allows a certain amount of overlap in operation (pipelining), allowing somewhat improved performance. It was 5% faster than FPM DRAM, which it began to replace in 1995, when Intel introduced the 430FX chipset that supported EDO DRAM.
To be precise, EDO DRAM begins data output on the falling edge of CAS, but does not stop the output when CAS rises again. It holds the output valid (thus extending the data output time) until either RAS is deasserted, or a new CAS falling edge selects a different column address.
Single-cycle EDO has the ability to carry out a complete memory transaction in one clock cycle. Otherwise, each sequential RAM access within the same page takes two clock cycles instead of three, once the page has been selected. EDO's performance and capabilities allowed it to somewhat replace the then-slow L2 caches of PCs. It created an opportunity to reduce the immense performance loss associated with a lack of L2 cache, while making systems cheaper to build. This was also good for notebooks due to difficulties with their limited form factor, and battery life limitations. An EDO system with L2 cache was tangibly faster than the older FPM/L2 combination.
Single-cycle EDO DRAM became very popular on video cards towards the end of the 1990s. It was very low cost, yet nearly as efficient for performance as the far more costly VRAM.
Burst EDO DRAM (BEDO DRAM)
An evolution of EDO DRAM, Burst EDO DRAM, could process four memory addresses in one burst, for a maximum of 5‐1‐1‐1, saving an additional three clocks over optimally designed EDO memory. It was done by adding an address counter on the chip to keep track of the next address. BEDO also added a pipeline stage allowing page-access cycle to be divided into two parts. During a memory-read operation, the first part accessed the data from the memory array to the output stage (second latch). The second part drove the data bus from this latch at the appropriate logic level. Since the data is already in the output buffer, quicker access time is achieved (up to 50% for large blocks of data) than with traditional EDO.
Although BEDO DRAM showed additional optimization over EDO, by the time it was available the market had made a significant investment towards synchronous DRAM, or SDRAM . Even though BEDO RAM was superior to SDRAM in some ways, the latter technology quickly displaced BEDO.
Synchronous dynamic RAM (SDRAM)
SDRAM significantly revises the asynchronous memory interface, adding a clock (and a clock enable) line. All other signals are received on the rising edge of the clock.
The /RAS and /CAS inputs no longer act as strobes, but are instead, along with /WE, part of a 3-bit command:
| /CS | /RAS | /CAS | /WE | Address | Command |
|---|---|---|---|---|---|
| H | x | x | x | x | Command inhibit (No operation) |
| L | H | H | H | x | No operation |
| L | H | H | L | x | Burst Terminate: stop a read or write burst in progress |
| L | H | L | H | column | Read from currently active row |
| L | H | L | L | column | Write to currently active row |
| L | L | H | H | row | Activate a row for read and write |
| L | L | H | L | x | Precharge (deactivate) the current row |
| L | L | L | H | x | Auto refresh: Refresh one row of each bank, using an internal counter |
| L | L | L | L | mode | Load mode register: Address bus specifies DRAM operation mode. |
The /OE line's function is extended to a per-byte "DQM" signal, which controls data input (writes) in addition to data output (reads). This allows DRAM chips to be wider than 8 bits while still supporting byte-granularity writes.
Many timing parameters remain under the control of the DRAM controller. For example, a minimum time must elapse between a row being activated and a read or write command. One important parameter must be programmed into the SDRAM chip itself, namely the CAS latency. This is the number of clock cycles allowed for internal operations between a read command and the first data word appearing on the data bus. The "Load mode register" command is used to transfer this value to the SDRAM chip. Other configurable parameters include the length of read and write bursts, i.e. the number of words transferred per read or write command.
The most significant change, and the primary reason that SDRAM has supplanted asynchronous RAM, is the support for multiple internal banks inside the DRAM chip. Using a few bits of "bank address" which accompany each command, a second bank can be activated and begin reading data while a read from the first bank is in progress. By alternating banks, an SDRAM device can keep the data bus continuously busy, in a way that asynchronous DRAM cannot.
Single data rate synchronous DRAM (SDR SDRAM)
Single data rate SDRAM (sometimes known as SDR) is a synchronous form of DRAM.
Double data rate synchronous DRAM (DDR SDRAM)
Double data rate SDRAM (DDR) was a later development of SDRAM, used in PC memory beginning in 2000. Subsequent versions are numbered sequentially (DDR2, DDR3, etc.). DDR SDRAM internally performs double-width accesses at the clock rate, and uses a double data rate interface to transfer one half on each clock edge. DDR2 and DDR3 increased this factor to 4× and 8×, respectively, delivering 4-word and 8-word bursts over 2 and 4 clock cycles, respectively. The internal access rate is mostly unchanged (200 million per second for DDR-400, DDR2-800 and DDR3-1600 memory), but each access transfers more data.
Direct Rambus DRAM (DRDRAM)
Direct RAMBUS DRAM (DRDRAM) was developed by Rambus.
Reduced Latency DRAM (RLDRAM)
Reduced Latency DRAM is a high performance double data rate (DDR) SDRAM that combines fast, random access with high bandwidth, mainly intended for networking and caching applications.
Graphics RAM
These are asynchronous and synchronous DRAMs designed for graphics-related tasks such as texture memory and framebuffers, and can be found on video cards.
Video DRAM (VRAM)
VRAM is a dual-ported variant of DRAM that was once commonly used to store the frame-buffer in some graphics adaptors.
Window DRAM (WRAM)
WRAM is a variant of VRAM that was once used in graphics adaptors such as the Matrox Millennium and ATI 3D Rage Pro. WRAM was designed to perform better and cost less than VRAM. WRAM offered up to 25% greater bandwidth than VRAM and accelerated commonly used graphical operations such as text drawing and block fills.[33]
Multibank DRAM (MDRAM)
Multibank DRAM is a type of specialized DRAM developed by MoSys. It is constructed from small memory banks of 256 KB, which are operated in an interleaved fashion, providing bandwidths suitable for graphics cards at a lower cost to memories such as SRAM. MDRAM also allows operations to two banks in a single clock cycle, permitting multiple concurrent accesses to occur if the accesses were independent. MDRAM was primarily used in graphic cards, such as those featuring the Tseng Labs ET6x00 chipsets. Boards based upon this chipset often had the unusual capacity of 2.25 MB because of MDRAM's ability to be implemented more easily with such capacities. A graphics card with 2.25 MB of MDRAM had enough memory to provide 24-bit color at a resolution of 1024×768—a very popular setting at the time.
Synchronous graphics RAM (SGRAM)

SGRAM is a specialized form of SDRAM for graphics adaptors. It adds functions such as bit masking (writing to a specified bit plane without affecting the others) and block write (filling a block of memory with a single colour). Unlike VRAM and WRAM, SGRAM is single-ported. However, it can open two memory pages at once, which simulates the dual-port nature of other video RAM technologies.
Graphics double data rate SDRAM (GDDR SDRAM)
Graphics double data rate SDRAM (GDDR SDRAM) is a type of specialized DDR SDRAM designed to be used as the main memory of graphics processing units (GPUs). GDDR SDRAM is distinct from commodity types of DDR SDRAM such as DDR3, although they share some core technologies. Their primary characteristics are higher clock frequencies for both the DRAM core and I/O interface, which provides greater memory bandwidth for GPUs. As of 2016, there are five successive generations of GDDR: GDDR2, GDDR3, GDDR4, GDDR5, and GDDR5X.
Pseudostatic RAM (PSRAM)

PSRAM or PSDRAM is dynamic RAM with built-in refresh and address-control circuitry to make it behave similarly to static RAM (SRAM). It combines the high density of DRAM with the ease of use of true SRAM. PSRAM (made by Numonyx) is used in the Apple iPhone and other embedded systems such as XFlar Platform.[34]
Some DRAM components have a "self-refresh mode". While this involves much of the same logic that is needed for pseudo-static operation, this mode is often equivalent to a standby mode. It is provided primarily to allow a system to suspend operation of its DRAM controller to save power without losing data stored in DRAM, rather not to allow operation without a separate DRAM controller as is the case with PSRAM.
An embedded variant of PSRAM is sold by MoSys under the name 1T-SRAM. It is technically DRAM, but behaves much like SRAM. It is used in Nintendo Gamecube and Wii video game consoles.
See also
Notes
- ↑ "How to "open" microchip and what's inside? : ZeptoBars". 2012-11-15. Retrieved 2016-04-02.
Micron MT4C1024 — 1 mebibit (220 bit) dynamic ram. Widely used in 286 and 386-era computers, early 90's. Die size - 8662x3969µm.
- ↑ S. Mittal, "A Survey of Architectural Techniques For DRAM Power Management", IJHPSA, 4(2), 110-119, 2012.
- ↑ Copeland B. Jack, and others (2006) Colossus: The Secrets of Bletchley Park's Codebreaking Computers Oxford: Oxford University Press, p301.
- ↑ Spec Sheet for Toshiba "TOSCAL" BC-1411
- ↑ Toshiba "Toscal" BC-1411 Desktop Calculator (The introduction date is listed here as November 1965, but this is a year too early and appears to be a typographical error.)
- ↑ http://inventors.about.com/library/weekly/aa100898.htm
- ↑ http://archive.computerhistory.org/resources/still-image/PENDING/X3665.2007/Semi_SIG/Notes%20from%20interview%20with%20John%20Reed.pdf
- ↑ "Lecture 12: DRAM Basics" (PDF). utah.edu. 2011-02-17. Retrieved 2015-03-10.
- ↑ David August (2004-11-23). "Lecture 20: Memory Technology" (PDF). cs.princeton.edu. pp. 3–5. Retrieved 2015-03-10.
- 1 2 3 4 5 6 7 8 9 Kenner pp. 24–30.
- ↑ Lest We Remember: Cold Boot Attacks on Encryption Keys, Halderman et al, USENIX Security 2008.
- ↑ Micron 4 Meg x 4 EDO DRAM data sheet
- ↑ cmx1024-3200.ai
- ↑ http://www.corsairmemory.com/corsair/products/specs/twinx1024-3200xl.pdf
- ↑ Kenner, p. 22
- ↑ Kenner, p. 24.
- ↑ Sallese, Jean-Michel (2002-06-20). "Principles of the 1T Dynamic Access Memory Concept on SOI" (PDF). MOS Modeling and Parameter Extraction Group Meeting. Wroclaw, Poland. Retrieved 2007-10-07.
- 1 2 Borucki, "Comparison of Accelerated DRAM Soft Error Rates Measured at Component and System Level", 46th Annual International Reliability Physics Symposium, Phoenix, 2008, pp. 482–487
- 1 2 Schroeder, Bianca et al. (2009). "DRAM errors in the wild: a large-scale field study". Proceedings of the Eleventh International Joint Conference on Measurement and Modeling of Computer Systems, pp. 193–204.
- 1 2 http://www.ece.rochester.edu/~xinli/usenix07/
- ↑ "ECC DRAM – Intelligent Memory". intelligentmemory.com. Retrieved 2015-01-16.
- ↑ http://spectrum.ieee.org/computing/hardware/drams-damning-defects-and-how-they-cripple-computers
- ↑ Li, Huang; Shen, Chu (2010). ""A Realistic Evaluation of Memory Hardware Errors and Software System Susceptibility". Usenix Annual Tech Conference 2010" (PDF).
- ↑ "Cycles, cells and platters: an empirical analysis of hardware failures on a million consumer PCs. Proceedings of the sixth conference on Computer systems (EuroSys '11). pp 343-356" (PDF). 2011.
- 1 2 "Center for Information Technology Policy » Lest We Remember: Cold Boot Attacks on Encryption Keys". Archived from the original on July 22, 2011. 080222 citp.princeton.edu
- ↑ Scheick, Leif Z.; Guertin, Steven M.; Swift, Gary M. (December 2000). "Analysis of radiation effects on individual DRAM cells". IEEE Trans. on Nuclear Science. 47 (6): 2534–2538. doi:10.1109/23.903804. ISSN 0018-9499. Retrieved 2013-08-08.
- ↑ Yoongu Kim; Ross Daly; Jeremie Kim; Chris Fallin; Ji Hye Lee; Donghyuk Lee; Chris Wilkerson; Konrad Lai; Onur Mutlu (June 24, 2014). "Flipping Bits in Memory Without Accessing Them: DRAM Disturbance Errors" (PDF). ece.cmu.edu. Retrieved March 10, 2015.
- ↑ S. Mittal et al., "A Survey Of Techniques for Architecting DRAM Caches", IEEE TPDS, 2015
- ↑
- ↑ Various Methods of DRAM Refresh Micron Technical Note TN-04-30
- ↑ Kenner, p. 13.
- 1 2 3 Kenner, p. 14
- ↑ The PC Guide, definition of WRAM.
- ↑ EE Times teardown of iPhone 3G
References
- Brent Keeth, R. Jacob Baker, Brian Johnson, Feng Lin. (2008). DRAM Circuit Design: Fundamental and High-Speed Topics. John Wiley & Sons.
- Bruce Jacob, Spencer W. Ng, David T. Wang (2008). Memory Systems: Cache, DRAM, Disk. Morgan Kaufmann Publishers.
External links
- DRAM density and speed trends has some interesting historical trend charts of DRAM density and speed from 1980.
- Benefits of Chipkill-Correct ECC for PC Server Main Memory — A 1997 discussion of SDRAM reliability—some interesting information on "soft errors" from cosmic rays, especially with respect to error-correcting code schemes
- Tezzaron Semiconductor Soft Error White Paper 1994 literature review of memory error rate measurements.
- Soft errors' impact on system reliability — Ritesh Mastipuram and Edwin C Wee, Cypress Semiconductor, 2004
- Scaling and Technology Issues for Soft Error Rates A Johnston—4th Annual Research Conference on Reliability Stanford University, October 2000
- Challenges and future directions for the scaling of dynamic random-access memory (DRAM) — J. A. Mandelman, R. H. Dennard, G. B. Bronner, J. K. DeBrosse, R. Divakaruni, Y. Li, and C. J. Radens, IBM 2002
- Ars Technica: RAM Guide
- David Tawei Wang (2005). "Modern DRAM Memory Systems: Performance Analysis and a High Performance, Power-Constrained DRAM-Scheduling Algorithm" (PDF). PhD thesis, University of Maryland, College Park. Retrieved 2007-03-10. A detailed description of current DRAM technology.
- Mitsubishi's 3D-RAM And Cache DRAM incorporate high performance, on-board SRAM cache
- Multi-port Cache DRAM — MP-RAM
- What every programmer should know about memory by Ulrich Drepper