World Wide Web

The World Wide Web (abbreviated WWW or the Web) is an information space where documents and other web resources are identified by Uniform Resource Locators (URLs), interlinked by hypertext links, and can be accessed via the Internet.[1] English scientist Tim Berners-Lee invented the World Wide Web in 1989. He wrote the first web browser computer programme in 1990 while employed at CERN in Switzerland.[2][3]
The World Wide Web has been central to the development of the Information Age and is the primary tool billions of people use to interact on the Internet.[4][5][6] Web pages are primarily text documents formatted and annotated with Hypertext Markup Language (HTML). In addition to formatted text, web pages may contain images, video, audio, and software components that are rendered in the user's web browser as coherent pages of multimedia content. Embedded hyperlinks permit users to navigate between web pages. Multiple web pages with a common theme, a common domain name, or both, make up a website. Website content can largely be provided by the publisher, or interactive where users contribute content or the content depends upon the user or their actions. Websites may be mostly informative, primarily for entertainment, or largely for commercial, governmental, or non-governmental organisational purposes. In the 2006 Great British Design Quest organised by the BBC and the Design Museum, the World Wide Web was voted among the top 10 British design icons.[7]
History


Tim Berners-Lee's vision of a global hyperlinked information system became a possibility by the second half of the 1980s. By 1985, the global Internet began to proliferate in Europe and in the Domain Name System (upon which the Uniform Resource Locator is built) came into being. In 1988 the first direct IP connection between Europe and North America was made and Berners-Lee began to openly discuss the possibility of a web-like system at CERN.[8] In March 1989 Berners-Lee issued a proposal to the management at CERN for a system called "Mesh" that referenced ENQUIRE, a database and software project he had built in 1980, which used the term "web" and described a more elaborate information management system based on links embedded in readable text: "Imagine, then, the references in this document all being associated with the network address of the thing to which they referred, so that while reading this document you could skip to them with a click of the mouse." Such a system, he explained, could be referred to using one of the existing meanings of the word hypertext, a term that he says was coined in the 1950s. There is no reason, the proposal continues, why such hypertext links could not encompass multimedia documents including graphics, speech and video, so that Berners-Lee goes on to use the term hypermedia.[9]
With help from his colleague and fellow hypertext enthusiast Robert Cailliau he published a more formal proposal on 12 November 1990 to build a "Hypertext project" called "WorldWideWeb" (one word) as a "web" of "hypertext documents" to be viewed by "browsers" using a client–server architecture.[10] At this point HTML and HTTP had already been in development for about two months and the first Web server was about a month from completing its first successful test. This proposal estimated that a read-only web would be developed within three months and that it would take six months to achieve "the creation of new links and new material by readers, [so that] authorship becomes universal" as well as "the automatic notification of a reader when new material of interest to him/her has become available." While the read-only goal was met, accessible authorship of web content took longer to mature, with the wiki concept, WebDAV, blogs, Web 2.0 and RSS/Atom.[11]

The proposal was modelled after the SGML reader Dynatext by Electronic Book Technology, a spin-off from the Institute for Research in Information and Scholarship at Brown University. The Dynatext system, licensed by CERN, was a key player in the extension of SGML ISO 8879:1986 to Hypermedia within HyTime, but it was considered too expensive and had an inappropriate licensing policy for use in the general high energy physics community, namely a fee for each document and each document alteration. A NeXT Computer was used by Berners-Lee as the world's first web server and also to write the first web browser, WorldWideWeb, in 1990. By Christmas 1990, Berners-Lee had built all the tools necessary for a working Web:[12] the first web browser (which was a web editor as well) and the first web server. The first web site,[13] which described the project itself, was published on 20 December 1990.[14]
The first web page may be lost, but Paul Jones of UNC-Chapel Hill in North Carolina announced in May 2013 that Berners-Lee gave him what he says is the oldest known web page during a 1991 visit to UNC. Jones stored it on a magneto-optical drive and on his NeXT computer.[15] On 6 August 1991, Berners-Lee published a short summary of the World Wide Web project on the newsgroup alt.hypertext.[16] This date is sometimes confused with the public availability of the first web servers, which had occurred months earlier. As another example of such confusion, several news media reported that the first photo on the Web was published by Berners-Lee in 1992, an image of the CERN house band Les Horribles Cernettes taken by Silvano de Gennaro; Gennaro has disclaimed this story, writing that media were "totally distorting our words for the sake of cheap sensationalism."[17]
The first server outside Europe was installed at the Stanford Linear Accelerator Center (SLAC) in Palo Alto, California, to host the SPIRES-HEP database. Accounts differ substantially as to the date of this event. The World Wide Web Consortium's timeline says December 1992,[18] whereas SLAC itself claims December 1991,[19][20] as does a W3C document titled A Little History of the World Wide Web.[21] The underlying concept of hypertext originated in previous projects from the 1960s, such as the Hypertext Editing System (HES) at Brown University, Ted Nelson's Project Xanadu, and Douglas Engelbart's oN-Line System (NLS). Both Nelson and Engelbart were in turn inspired by Vannevar Bush's microfilm-based memex, which was described in the 1945 essay "As We May Think".[22]
Berners-Lee's breakthrough was to marry hypertext to the Internet. In his book Weaving The Web, he explains that he had repeatedly suggested that a marriage between the two technologies was possible to members of both technical communities, but when no one took up his invitation, he finally assumed the project himself. In the process, he developed three essential technologies:
- a system of globally unique identifiers for resources on the Web and elsewhere, the universal document identifier (UDI), later known as uniform resource locator (URL) and uniform resource identifier (URI);
- the publishing language HyperText Markup Language (HTML);
- the Hypertext Transfer Protocol (HTTP).[23]
The World Wide Web had a number of differences from other hypertext systems available at the time. The Web required only unidirectional links rather than bidirectional ones, making it possible for someone to link to another resource without action by the owner of that resource. It also significantly reduced the difficulty of implementing web servers and browsers (in comparison to earlier systems), but in turn presented the chronic problem of link rot. Unlike predecessors such as HyperCard, the World Wide Web was non-proprietary, making it possible to develop servers and clients independently and to add extensions without licensing restrictions. On 30 April 1993, CERN announced that the World Wide Web would be free to anyone, with no fees due.[24] Coming two months after the announcement that the server implementation of the Gopher protocol was no longer free to use, this produced a rapid shift away from Gopher and towards the Web. An early popular web browser was ViolaWWW for Unix and the X Windowing System.

Scholars generally agree that a turning point for the World Wide Web began with the introduction[25] of the Mosaic web browser[26] in 1993, a graphical browser developed by a team at the National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign (NCSA-UIUC), led by Marc Andreessen. Funding for Mosaic came from the U.S. High-Performance Computing and Communications Initiative and the High Performance Computing and Communication Act of 1991, one of several computing developments initiated by U.S. Senator Al Gore.[27] Prior to the release of Mosaic, graphics were not commonly mixed with text in web pages and the web's popularity was less than older protocols in use over the Internet, such as Gopher and Wide Area Information Servers (WAIS). Mosaic's graphical user interface allowed the Web to become, by far, the most popular Internet protocol. The World Wide Web Consortium (W3C) was founded by Tim Berners-Lee after he left the European Organization for Nuclear Research (CERN) in October 1994. It was founded at the Massachusetts Institute of Technology Laboratory for Computer Science (MIT/LCS) with support from the Defense Advanced Research Projects Agency (DARPA), which had pioneered the Internet; a year later, a second site was founded at INRIA (a French national computer research lab) with support from the European Commission DG InfSo; and in 1996, a third continental site was created in Japan at Keio University. By the end of 1994, the total number of websites was still relatively small, but many notable websites were already active that foreshadowed or inspired today's most popular services.
Connected by the Internet, other websites were created around the world. This motivated international standards development for protocols and formatting. Berners-Lee continued to stay involved in guiding the development of web standards, such as the markup languages to compose web pages and he advocated his vision of a Semantic Web. The World Wide Web enabled the spread of information over the Internet through an easy-to-use and flexible format. It thus played an important role in popularising use of the Internet.[28] Although the two terms are sometimes conflated in popular use, World Wide Web is not synonymous with Internet.[29] The Web is an information space containing hyperlinked documents and other resources, identified by their URIs.[30] It is implemented as both client and server software using Internet protocols such as TCP/IP and HTTP. Berners-Lee was knighted in 2004 by Queen Elizabeth II for "services to the global development of the Internet".[31][32]
Function

The terms Internet and World Wide Web are often used without much distinction. However, the two are not the same. The Internet is a global system of interconnected computer networks. In contrast, the World Wide Web is a global collection of documents and other resources, linked by hyperlinks and URIs. Web resources are usually accessed using HTTP, which is one of many Internet communication protocols.[33]
Viewing a web page on the World Wide Web normally begins either by typing the URL of the page into a web browser, or by following a hyperlink to that page or resource. The web browser then initiates a series of background communication messages to fetch and display the requested page. In the 1990s, using a browser to view web pages—and to move from one web page to another through hyperlinks—came to be known as 'browsing,' 'web surfing' (after channel surfing), or 'navigating the Web'. Early studies of this new behaviour investigated user patterns in using web browsers. One study, for example, found five user patterns: exploratory surfing, window surfing, evolved surfing, bounded navigation and targeted navigation.[34]
The following example demonstrates the functioning of a web browser when accessing a page at the URL http://www.example.org/home.html. The browser resolves the server name of the URL (www.example.org) into an Internet Protocol address using the globally distributed Domain Name System (DNS). This lookup returns an IP address such as 203.0.113.4 or 2001:db8:2e::7334. The browser then requests the resource by sending an HTTP request across the Internet to the computer at that address. It requests service from a specific TCP port number that is well known for the HTTP service, so that the receiving host can distinguish an HTTP request from other network protocols it may be servicing. The HTTP protocol normally uses port number 80. The content of the HTTP request can be as simple as two lines of text:
GET /home.html HTTP/1.1
Host: www.example.org
The computer receiving the HTTP request delivers it to web server software listening for requests on port 80. If the web server can fulfil the request it sends an HTTP response back to the browser indicating success:
HTTP/1.0 200 OK
Content-Type: text/html; charset=UTF-8
followed by the content of the requested page. HyperText Markup Language (HTML) for a basic web page might look like this:
<html>
<head>
<title>Example.org – The World Wide Web</title>
</head>
<body>
<p>The World Wide Web, abbreviated as WWW and commonly known ...</p>
</body>
</html>
The web browser parses the HTML and interprets the markup (<title>, <p> for paragraph, and such) that surrounds the words to format the text on the screen. Many web pages use HTML to reference the URLs of other resources such as images, other embedded media, scripts that affect page behaviour, and Cascading Style Sheets that affect page layout. The browser makes additional HTTP requests to the web server for these other Internet media types. As it receives their content from the web server, the browser progressively renders the page onto the screen as specified by its HTML and these additional resources.
Linking
Most web pages contain hyperlinks to other related pages and perhaps to downloadable files, source documents, definitions and other web resources. In the underlying HTML, a hyperlink looks like this:
<a href="http://www.example.org/home.html">Example.org Homepage</a>
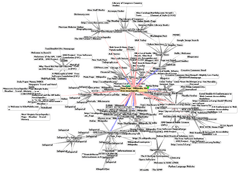
Such a collection of useful, related resources, interconnected via hypertext links is dubbed a web of information. Publication on the Internet created what Tim Berners-Lee first called the WorldWideWeb (in its original CamelCase, which was subsequently discarded) in November 1990.[10]
The hyperlink structure of the WWW is described by the webgraph: the nodes of the webgraph correspond to the web pages (or URLs) the directed edges between them to the hyperlinks. Over time, many web resources pointed to by hyperlinks disappear, relocate, or are replaced with different content. This makes hyperlinks obsolete, a phenomenon referred to in some circles as link rot, and the hyperlinks affected by it are often called dead links. The ephemeral nature of the Web has prompted many efforts to archive web sites. The Internet Archive, active since 1996, is the best known of such efforts.
Dynamic updates of web pages
JavaScript is a scripting language that was initially developed in 1995 by Brendan Eich, then of Netscape, for use within web pages.[35] The standardised version is ECMAScript.[35] To make web pages more interactive, some web applications also use JavaScript techniques such as Ajax (asynchronous JavaScript and XML). Client-side script is delivered with the page that can make additional HTTP requests to the server, either in response to user actions such as mouse movements or clicks, or based on elapsed time. The server's responses are used to modify the current page rather than creating a new page with each response, so the server needs only to provide limited, incremental information. Multiple Ajax requests can be handled at the same time, and users can interact with the page while data is retrieved. Web pages may also regularly poll the server to check whether new information is available.[36]
WWW prefix
Many hostnames used for the World Wide Web begin with www because of the long-standing practice of naming Internet hosts according to the services they provide. The hostname of a web server is often www, in the same way that it may be ftp for an FTP server, and news or nntp for a USENET news server. These host names appear as Domain Name System (DNS) or subdomain names, as in www.example.com. The use of www is not required by any technical or policy standard and many web sites do not use it; indeed, the first ever web server was called nxoc01.cern.ch.[37] According to Paolo Palazzi,[38] who worked at CERN along with Tim Berners-Lee, the popular use of www as subdomain was accidental; the World Wide Web project page was intended to be published at www.cern.ch while info.cern.ch was intended to be the CERN home page, however the DNS records were never switched, and the practice of prepending www to an institution's website domain name was subsequently copied. Many established websites still use the prefix, or they employ other subdomain names such as www2, secure or en for special purposes. Many such web servers are set up so that both the main domain name (e.g., example.com) and the www subdomain (e.g., www.example.com) refer to the same site; others require one form or the other, or they may map to different web sites. The use of a subdomain name is useful for load balancing incoming web traffic by creating a CNAME record that points to a cluster of web servers. Since, currently, only a subdomain can be used in a CNAME, the same result cannot be achieved by using the bare domain root.
When a user submits an incomplete domain name to a web browser in its address bar input field, some web browsers automatically try adding the prefix "www" to the beginning of it and possibly ".com", ".org" and ".net" at the end, depending on what might be missing. For example, entering 'microsoft' may be transformed to http://www.microsoft.com/ and 'openoffice' to http://www.openoffice.org. This feature started appearing in early versions of Mozilla Firefox, when it still had the working title 'Firebird' in early 2003, from an earlier practice in browsers such as Lynx.[39] It is reported that Microsoft was granted a US patent for the same idea in 2008, but only for mobile devices.[40]
In English, www is usually read as double-u double-u double-u.[41] Some users pronounce it dub-dub-dub, particularly in New Zealand. Stephen Fry, in his "Podgrammes" series of podcasts, pronounces it wuh wuh wuh. The English writer Douglas Adams once quipped in The Independent on Sunday (1999): "The World Wide Web is the only thing I know of whose shortened form takes three times longer to say than what it's short for".[42] In Mandarin Chinese, World Wide Web is commonly translated via a phono-semantic matching to wàn wéi wǎng (万维网), which satisfies www and literally means "myriad dimensional net",[43] a translation that reflects the design concept and proliferation of the World Wide Web. Tim Berners-Lee's web-space states that World Wide Web is officially spelled as three separate words, each capitalised, with no intervening hyphens.[44] Use of the www prefix has been declining, especially when Web 2.0 web applications sought to brand their domain names and make them easily pronounceable.[45] As the mobile web grew in popularity, services like Gmail.com, Outlook.com, MySpace.com, Facebook.com and Twitter.com are most often mentioned without adding "www." (or, indeed, ".com") to the domain.
Scheme specifiers
The scheme specifiers http:// and https:// at the start of a web URI refer to Hypertext Transfer Protocol or HTTP Secure, respectively. They specify the communication protocol to use for the request and response. The HTTP protocol is fundamental to the operation of the World Wide Web, and the added encryption layer in HTTPS is essential when browsers send or retrieve confidential data, such as passwords or banking information. Web browsers usually automatically prepend http:// to user-entered URIs, if omitted.
Web security
For criminals, the Web has become a venue to spread malware and engage in a range of cybercrimes, including identity theft, fraud, espionage and intelligence gathering.[46] Web-based vulnerabilities now outnumber traditional computer security concerns,[47][48] and as measured by Google, about one in ten web pages may contain malicious code.[49] Most web-based attacks take place on legitimate websites, and most, as measured by Sophos, are hosted in the United States, China and Russia.[50] The most common of all malware threats is SQL injection attacks against websites.[51] Through HTML and URIs, the Web was vulnerable to attacks like cross-site scripting (XSS) that came with the introduction of JavaScript[52] and were exacerbated to some degree by Web 2.0 and Ajax web design that favours the use of scripts.[53] Today by one estimate, 70% of all websites are open to XSS attacks on their users.[54] Phishing is another common threat to the Web. "SA, the Security Division of EMC, today announced the findings of its January 2013 Fraud Report, estimating the global losses from phishing at $1.5 Billion in 2012".[55] Two of the well-known phishing methods are Covert Redirect and Open Redirect.
Proposed solutions vary. Large security companies like McAfee already design governance and compliance suites to meet post-9/11 regulations,[56] and some, like Finjan have recommended active real-time inspection of programming code and all content regardless of its source.[46] Some have argued that for enterprises to see Web security as a business opportunity rather than a cost centre,[57] while others call for "ubiquitous, always-on digital rights management" enforced in the infrastructure to replace the hundreds of companies that secure data and networks.[58] Jonathan Zittrain has said users sharing responsibility for computing safety is far preferable to locking down the Internet.[59]
Privacy
Every time a client requests a web page, the server can identify the request's IP address and usually logs it. Also, unless set not to do so, most web browsers record requested web pages in a viewable history feature, and usually cache much of the content locally. Unless the server-browser communication uses HTTPS encryption, web requests and responses travel in plain text across the Internet and can be viewed, recorded, and cached by intermediate systems. When a web page asks for, and the user supplies, personally identifiable information—such as their real name, address, e-mail address, etc.—web-based entities can associate current web traffic with that individual. If the website uses HTTP cookies, username and password authentication, or other tracking techniques, it can relate other web visits, before and after, to the identifiable information provided. In this way it is possible for a web-based organisation to develop and build a profile of the individual people who use its site or sites. It may be able to build a record for an individual that includes information about their leisure activities, their shopping interests, their profession, and other aspects of their demographic profile. These profiles are obviously of potential interest to marketeers, advertisers and others. Depending on the website's terms and conditions and the local laws that apply information from these profiles may be sold, shared, or passed to other organisations without the user being informed. For many ordinary people, this means little more than some unexpected e-mails in their in-box, or some uncannily relevant advertising on a future web page. For others, it can mean that time spent indulging an unusual interest can result in a deluge of further targeted marketing that may be unwelcome. Law enforcement, counter terrorism and espionage agencies can also identify, target and track individuals based on their interests or proclivities on the Web.
Social networking sites try to get users to use their real names, interests, and locations, rather than pseudonyms. These website's leaders believe this makes the social networking experience more engaging for users. On the other hand, uploaded photographs or unguarded statements can be identified to an individual, who may regret this exposure. Employers, schools, parents, and other relatives may be influenced by aspects of social networking profiles, such as text posts or digital photos, that the posting individual did not intend for these audiences. On-line bullies may make use of personal information to harass or stalk users. Modern social networking websites allow fine grained control of the privacy settings for each individual posting, but these can be complex and not easy to find or use, especially for beginners.[60] Photographs and videos posted onto websites have caused particular problems, as they can add a person's face to an on-line profile. With modern and potential facial recognition technology, it may then be possible to relate that face with other, previously anonymous, images, events and scenarios that have been imaged elsewhere. Because of image caching, mirroring and copying, it is difficult to remove an image from the World Wide Web.
Standards
Many formal standards and other technical specifications and software define the operation of different aspects of the World Wide Web, the Internet, and computer information exchange. Many of the documents are the work of the World Wide Web Consortium (W3C), headed by Berners-Lee, but some are produced by the Internet Engineering Task Force (IETF) and other organisations.
Usually, when web standards are discussed, the following publications are seen as foundational:
- Recommendations for markup languages, especially HTML and XHTML, from the W3C. These define the structure and interpretation of hypertext documents.
- Recommendations for stylesheets, especially CSS, from the W3C.
- Standards for ECMAScript (usually in the form of JavaScript), from Ecma International.
- Recommendations for the Document Object Model, from W3C.
Additional publications provide definitions of other essential technologies for the World Wide Web, including, but not limited to, the following:
- Uniform Resource Identifier (URI), which is a universal system for referencing resources on the Internet, such as hypertext documents and images. URIs, often called URLs, are defined by the IETF's RFC 3986 / STD 66: Uniform Resource Identifier (URI): Generic Syntax, as well as its predecessors and numerous URI scheme-defining RFCs;
- HyperText Transfer Protocol (HTTP), especially as defined by RFC 2616: HTTP/1.1 and RFC 2617: HTTP Authentication, which specify how the browser and server authenticate each other.
Accessibility
There are methods for accessing the Web in alternative mediums and formats to facilitate use by individuals with disabilities. These disabilities may be visual, auditory, physical, speech-related, cognitive, neurological, or some combination. Accessibility features also help people with temporary disabilities, like a broken arm, or ageing users as their abilities change.[61] The Web receives information as well as providing information and interacting with society. The World Wide Web Consortium claims that it is essential that the Web be accessible, so it can provide equal access and equal opportunity to people with disabilities.[62] Tim Berners-Lee once noted, "The power of the Web is in its universality. Access by everyone regardless of disability is an essential aspect."[61] Many countries regulate web accessibility as a requirement for websites.[63] International cooperation in the W3C Web Accessibility Initiative led to simple guidelines that web content authors as well as software developers can use to make the Web accessible to persons who may or may not be using assistive technology.[61][64]
Internationalisation
The W3C Internationalisation Activity assures that web technology works in all languages, scripts, and cultures.[65] Beginning in 2004 or 2005, Unicode gained ground and eventually in December 2007 surpassed both ASCII and Western European as the Web's most frequently used character encoding.[66] Originally RFC 3986 allowed resources to be identified by URI in a subset of US-ASCII. RFC 3987 allows more characters—any character in the Universal Character Set—and now a resource can be identified by IRI in any language.[67]
Statistics
Between 2005 and 2010, the number of web users doubled, and was expected to surpass two billion in 2010.[68] Early studies in 1998 and 1999 estimating the size of the Web using capture/recapture methods showed that much of the web was not indexed by search engines and the Web was much larger than expected.[69][70] According to a 2001 study, there was a massive number, over 550 billion, of documents on the Web, mostly in the invisible Web, or Deep Web.[71] A 2002 survey of 2,024 million web pages[72] determined that by far the most web content was in the English language: 56.4%; next were pages in German (7.7%), French (5.6%), and Japanese (4.9%). A more recent study, which used web searches in 75 different languages to sample the Web, determined that there were over 11.5 billion web pages in the publicly indexable web as of the end of January 2005.[73] As of March 2009, the indexable web contains at least 25.21 billion pages.[74] On 25 July 2008, Google software engineers Jesse Alpert and Nissan Hajaj announced that Google Search had discovered one trillion unique URLs.[75] As of May 2009, over 109.5 million domains operated.[76] Of these, 74% were commercial or other domains operating in the generic top-level domain com.[76] Statistics measuring a website's popularity, such as the Alexa Internet rankings, are usually based either on the number of page views or on associated server "hits" (file requests) that it receives.
Speed issues
Frustration over congestion issues in the Internet infrastructure and the high latency that results in slow browsing, "freezing" of Web pages, and slow loading of websites has led to a pejorative name for the World Wide Web: the World Wide Wait.[77] Speeding up the Internet is an ongoing discussion over the use of peering and QoS technologies. Other solutions to reduce the congestion can be found at W3C.[78] Guidelines for web response times are:[79]
- 0.1 second (one tenth of a second). Ideal response time. The user does not sense any interruption.
- 1 second. Highest acceptable response time. Download times above 1 second interrupt the user experience.
- 10 seconds. Unacceptable response time. The user experience is interrupted and the user is likely to leave the site or system.
Web caching
A web cache is a server computer located either on the public Internet, or within an enterprise that stores recently accessed web pages to improve response time for users when the same content is requested within a certain time after the original request. Most web browsers also implement a browser cache for recently obtained data, usually on the local disk drive. HTTP requests by a browser may ask only for data that has changed since the last access. Web pages and resources may contain expiration information to control caching to secure sensitive data, such as in online banking, or to facilitate frequently updated sites, such as news media. Even sites with highly dynamic content may permit basic resources to be refreshed only occasionally. Web site designers find it worthwhile to collate resources such as CSS data and JavaScript into a few site-wide files so that they can be cached efficiently. Enterprise firewalls often cache Web resources requested by one user for the benefit of many users. Some search engines store cached content of frequently accessed websites.
See also
- Electronic publishing
- Internet metaphors
- Internet security
- Lists of websites
- Prestel
- Streaming media
- Web 2.0
- Web development tools
- Web literacy
- Webgraph
References
- ↑ "What is the difference between the Web and the Internet?". W3C Help and FAQ. W3C. 2009. Retrieved 16 July 2015.
- ↑ McPherson, Stephanie Sammartino (2009). Tim Berners-Lee: Inventor of the World Wide Web. Twenty-First Century Books.
- ↑ Quittner, Joshua (29 March 1999). "Network Designer Tim Berners-Lee". Time Magazine. Retrieved 17 May 2010. (subscription required (help)).
He wove the World Wide Web and created a mass medium for the 21st century. The World Wide Web is Berners-Lee's alone. He designed it. He loosed it on the world. And he more than anyone else has fought to keep it open, nonproprietary and free.
- ↑ "World Wide Web Timeline". Pew Research Center. 11 March 2014. Retrieved 1 August 2015.
- ↑ Dewey, Caitlin (12 March 2014). "36 Ways the Web Has Changed Us". The Washington Post. Retrieved 1 August 2015.
- ↑ "Internet Live Stats". Retrieved 1 August 2015.
- ↑ "Concorde voted the UK's top icon". BBC. 18 November 2016.
- ↑ http://cs.wellesley.edu/~cs315/BOOKS/TBL12.pdf
- ↑ Berners-Lee, Tim (March 1989). "Information Management: A Proposal". W3C. Retrieved 27 July 2009.
- 1 2 Berners-Lee, Tim; Cailliau, Robert (12 November 1990). "WorldWideWeb: Proposal for a HyperText Project". Retrieved 12 May 2015.
- ↑ "Tim Berners-Lee's original World Wide Web browser".
With recent phenomena like blogs and wikis, the Web is beginning to develop the kind of collaborative nature that its inventor envisaged from the start.
- ↑ "Tim Berners-Lee: client". W3.org. Retrieved 27 July 2009.
- ↑ "First Web pages". W3.org. Retrieved 27 July 2009.
- ↑ "The birth of the web". CERN. Retrieved 23 December 2015.
- ↑ Murawski, John (24 May 2013). "Hunt for world's oldest WWW page leads to UNC Chapel Hill". News & Observer.
- ↑ "Short summary of the World Wide Web project". Google. 6 August 1991. Retrieved 27 July 2009.
- ↑ "Silvano de Gennaro disclaims 'the first photo on the Web'". Retrieved 27 July 2012.
If you read well our website, it says that it was, to our knowledge, the 'first photo of a band'. Dozens of media are totally distorting our words for the sake of cheap sensationalism. Nobody knows which was the first photo on the Web.
- ↑ "W3C timeline". Retrieved 30 March 2010.
- ↑ "The Early World Wide Web at SLAC".
- ↑ "About SPIRES". Retrieved 30 March 2010.
- ↑ "A Little History of the World Wide Web".
- ↑ Conklin, Jeff (1987), IEEE Computer, 20 (9), pp. 17–41
- ↑ "Inventor of the Week Archive: The World Wide Web". Massachusetts Institute of Technology: MIT School of Engineering. Archived from the original on 8 June 2010. Retrieved 23 July 2009.
- ↑ "Ten Years Public Domain for the Original Web Software". Tenyears-www.web.cern.ch. 30 April 2003. Retrieved 27 July 2009.
- ↑ "Mosaic Web Browser History – NCSA, Marc Andreessen, Eric Bina". Livinginternet.com. Retrieved 27 July 2009.
- ↑ "NCSA Mosaic – September 10, 1993 Demo". Totic.org. Retrieved 27 July 2009.
- ↑ "Vice President Al Gore's ENIAC Anniversary Speech". Cs.washington.edu. 14 February 1996. Retrieved 27 July 2009.
- ↑ "Internet legal definition of Internet". West's Encyclopedia of American Law, edition 2. Free Online Law Dictionary. 15 July 2009. Retrieved 25 November 2008.
- ↑ "WWW (World Wide Web) Definition". TechTerms. Retrieved 19 February 2010.
- ↑ Jacobs, Ian; Walsh, Norman (15 December 2004). "Architecture of the World Wide Web, Volume One". Introduction: W3C. Retrieved 11 February 2015.
- ↑ "Supplement no.1, Diplomatic and Overseas List, K.B.E." (PDF). thegazette.co.uk. The Gazette. 31 December 2003. Retrieved 7 February 2016.
- ↑ "Web's inventor gets a knighthood". BBC. 31 December 2003. Retrieved 25 May 2008.
- ↑ "What is the difference between the Web and the Internet?". World Wide Web Consortium. Retrieved 18 April 2016.
- ↑ Muylle, Steve; Rudy Moenaert; Marc Despont (1999). "A grounded theory of World Wide Web search behaviour". Journal of Marketing Communications. 5 (3): 143. doi:10.1080/135272699345644.
- 1 2 Hamilton, Naomi (31 July 2008). "The A-Z of Programming Languages: JavaScript". Computerworld. IDG. Retrieved 12 May 2009.
- ↑ Buntin, Seth (23 September 2008). "jQuery Polling plugin". Retrieved 2009-08-22.
- ↑ Berners-Lee, Tim. "Frequently asked questions by the Press". W3C. Retrieved 27 July 2009.
- ↑ Palazzi, P (2011) 'The Early Days of the WWW at CERN'
- ↑ "automatically adding www.___.com". mozillaZine. 16 May 2003. Retrieved 27 May 2009.
- ↑ Masnick, Mike (7 July 2008). "Microsoft Patents Adding 'www.' And '.com' To Text". Techdirt. Retrieved 27 May 2009.
- ↑ "Audible pronunciation of 'WWW'". Oxford University Press. Retrieved 25 May 2014.
- ↑ Simonite, Tom (July 22, 2008). "Help us find a better way to pronounce www". newscientist.com. NewScientist, Technology. Retrieved 7 February 2016.
- ↑ "MDBG Chinese-English dictionary – Translate". Retrieved 27 July 2009.
- ↑ "Frequently asked questions by the Press – Tim BL". W3.org. Retrieved 27 July 2009.
- ↑ Castelluccio, Michael (2010). "It's not your grandfather's Internet.". thefreelibrary.com. Institute of Management Accountants. Retrieved 7 February 2016.
- 1 2 Ben-Itzhak, Yuval (18 April 2008). "Infosecurity 2008 – New defence strategy in battle against e-crime". ComputerWeekly. Reed Business Information. Retrieved 20 April 2008.
- ↑ Christey, Steve & Martin, Robert A. (22 May 2007). "Vulnerability Type Distributions in CVE (version 1.1)". MITRE Corporation. Retrieved 7 June 2008.
- ↑ "Symantec Internet Security Threat Report: Trends for July–December 2007 (Executive Summary)" (PDF). XIII. Symantec Corp. April 2008: 1–2. Retrieved 11 May 2008.
- ↑ "Google searches web's dark side". BBC News. 11 May 2007. Retrieved 26 April 2008.
- ↑ "Security Threat Report (Q1 2008)" (PDF). Sophos. Retrieved 24 April 2008.
- ↑ "Security threat report" (PDF). Sophos. July 2008. Retrieved 24 August 2008.
- ↑ Fogie, Seth, Jeremiah Grossman, Robert Hansen, and Anton Rager (2007). Cross Site Scripting Attacks: XSS Exploits and Defense (PDF). Syngress, Elsevier Science & Technology. pp. 68–69, 127. ISBN 1-59749-154-3. Archived from the original (PDF) on 25 June 2008. Retrieved 6 June 2008.
- ↑ O'Reilly, Tim (30 September 2005). "What Is Web 2.0". O'Reilly Media. pp. 4–5. Retrieved 4 June 2008. and AJAX web applications can introduce security vulnerabilities like "client-side security controls, increased attack surfaces, and new possibilities for Cross-Site Scripting (XSS)", in Ritchie, Paul (March 2007). "The security risks of AJAX/web 2.0 applications" (PDF). Infosecurity. Elsevier. Archived from the original (PDF) on 25 June 2008. Retrieved 6 June 2008. which cites Hayre, Jaswinder S. & Kelath, Jayasankar (22 June 2006). "Ajax Security Basics". SecurityFocus. Retrieved 6 June 2008.
- ↑ Berinato, Scott (1 January 2007). "Software Vulnerability Disclosure: The Chilling Effect". CSO. CXO Media. p. 7. Archived from the original on 18 April 2008. Retrieved 7 June 2008.
- ↑ "2012 Global Losses From phishing Estimated At $1.5 Bn". FirstPost. 20 February 2013. Retrieved 21 December 2014.
- ↑ Prince, Brian (9 April 2008). "McAfee Governance, Risk and Compliance Business Unit". eWEEK. Ziff Davis Enterprise Holdings. Retrieved 25 April 2008.
- ↑ Preston, Rob (12 April 2008). "Down To Business: It's Past Time To Elevate The Infosec Conversation". InformationWeek. United Business Media. Retrieved 25 April 2008.
- ↑ Claburn, Thomas (6 February 2007). "RSA's Coviello Predicts Security Consolidation". InformationWeek. United Business Media. Retrieved 25 April 2008.
- ↑ Duffy Marsan, Carolyn (9 April 2008). "How the iPhone is killing the 'Net". Network World. IDG. Retrieved 17 April 2008.
- ↑ boyd, danah; Hargittai, Eszter (July 2010). "Facebook privacy settings: Who cares?". First Monday. University of Illinois at Chicago. 15 (8).
- 1 2 3 "Web Accessibility Initiative (WAI)". World Wide Web Consortium. Archived from the original on 2 April 2009. Retrieved 7 April 2009.
- ↑ "Developing a Web Accessibility Business Case for Your Organization: Overview". World Wide Web Consortium. Retrieved 7 April 2009.
- ↑ "Legal and Policy Factors in Developing a Web Accessibility Business Case for Your Organization". World Wide Web Consortium. Retrieved 7 April 2009.
- ↑ "Web Content Accessibility Guidelines (WCAG) Overview". World Wide Web Consortium. Retrieved 7 April 2009.
- ↑ "Internationalization (I18n) Activity". World Wide Web Consortium. Retrieved 10 April 2009.
- ↑ Davis, Mark (5 April 2008). "Moving to Unicode 5.1". Google. Retrieved 10 April 2009.
- ↑ "World Wide Web Consortium Supports the IETF URI Standard and IRI Proposed Standard" (Press release). World Wide Web Consortium. 26 January 2005. Retrieved 10 April 2009.
- ↑ Lynn, Jonathan (19 October 2010). "Internet users to exceed 2 billion ...". Reuters. Retrieved 9 February 2011.
- ↑ S. Lawrence, C.L. Giles, "Searching the World Wide Web," Science, 280(5360), 98–100, 1998.
- ↑ S. Lawrence, C.L. Giles, "Accessibility of Information on the Web," Nature, 400, 107–109, 1999.
- ↑ "The 'Deep' Web: Surfacing Hidden Value". Brightplanet.com. Archived from the original on 4 April 2008. Retrieved 27 July 2009.
- ↑ "Distribution of languages on the Internet". Netz-tipp.de. Retrieved 27 July 2009.
- ↑ Alessio Signorini. "The Indexable Web is More than 11.5 Billion Pages" (PDF). citeseerx.ist.psu.edu. Retrieved 4 February 2015.
- ↑ "The size of the World Wide Web". Worldwidewebsize.com. Retrieved 27 July 2009.
- ↑ Alpert, Jesse; Hajaj, Nissan (25 July 2008). "We knew the web was big...". The Official Google Blog.
- 1 2 "Domain Counts & Internet Statistics". Name Intelligence. Retrieved 17 May 2009.
- ↑ "World Wide Wait". TechEncyclopedia. United Business Media. Retrieved 10 April 2009.
- ↑ Khare, Rohit & Jacobs, Ian (1999). "W3C Recommendations Reduce 'World Wide Wait'". World Wide Web Consortium. Retrieved 10 April 2009.
- ↑ Nielsen, Jakob (from Miller 1968; Card 1991) (1994). "5". Usability Engineering: Response Times: The Three Important Limits. Morgan Kaufmann. Retrieved 10 April 2009.
{kind=link}
Further reading
- Berners-Lee, Tim; Bray, Tim; Connolly, Dan; Cotton, Paul; Fielding, Roy; Jeckle, Mario; Lilley, Chris; Mendelsohn, Noah; Orchard, David; Walsh, Norman; Williams, Stuart (15 December 2004). "Architecture of the World Wide Web, Volume One". Version 20041215. W3C.
- Berners-Lee, Tim (August 1996). "The World Wide Web: Past, Present and Future".
- Fielding, R.; Gettys, J.; Mogul, J.; Frystyk, H.; Masinter, L.; Leach, P.; Berners-Lee, T. (June 1999). "Hypertext Transfer Protocol – HTTP/1.1". Request For Comments 2616. Information Sciences Institute.
- Niels Brügger, ed. Web History (2010) 362 pages; Historical perspective on the World Wide Web, including issues of culture, content, and preservation.
- Polo, Luciano (2003). "World Wide Web Technology Architecture: A Conceptual Analysis". New Devices.
- Skau, H.O. (March 1990). "The World Wide Web and Health Information". New Devices.
External links
| Wikimedia Commons has media related to W3C. |
| Wikibooks has a book on the topic of: Nets, Webs and the Information Infrastructure |
- The first website
- Early archive of the first Web site
- Internet Statistics: Growth and Usage of the Web and the Internet
- Living Internet A comprehensive history of the Internet, including the World Wide Web
- Web Design and Development at DMOZ
- World Wide Web Consortium (W3C)
- W3C Recommendations Reduce "World Wide Wait"
- World Wide Web Size Daily estimated size of the World Wide Web
- Antonio A. Casilli, Some Elements for a Sociology of Online Interactions
- The Erdős Webgraph Server offers weekly updated graph representation of a constantly increasing fraction of the WWW
- The 25th Anniversary of the World Wide Web is an animated video produced by USAID and TechChange which explores the role of the WWW in addressing extreme poverty
| General | |
|---|---|
| Software packages | |
| Community | |
| Licenses | |
| License types and standards |
|
| Challenges | |
| Related topics | |
| |