Speech production
Speech production is the process by which thoughts are translated into speech. This includes the selection of words, the organization of relevant grammatical forms, and then the articulation of the resulting sounds by the motor system using the vocal apparatus. Speech production can be spontaneous such as when a person creates the words of a conversation, reactive such as when they name a picture or read aloud a written word, or imitative, such as in speech repetition. Speech production is not the same as language production since language can also be produced manually by signs.
In ordinary fluent conversation people pronounce roughly four syllables, ten or twelve phonemes and two to three words out of their vocabulary (that can contain 10 to 100 thousand words) each second.[1] Errors in speech production are relatively rare occurring at a rate of about once in every 900 words in spontaneous speech.[2] Words that are commonly spoken or learned early in life or easily imagined are quicker to say than ones that are rarely said, learnt later in life, or are abstract.[3][4]
Normally speech is created with pulmonary pressure provided by the lungs that generates sound by phonation through the glottis in the larynx that then is modified by the vocal tract into different vowels and consonants. However speech production can occur without the use of the lungs and glottis in alaryngeal speech by using the upper parts of the vocal tract. An example of such alaryngeal speech is Donald Duck talk.[5]
The vocal production of speech may be associated with the production of hand gestures that act to enhance the comprehensibility of what is being said.[6]
The development of speech production throughout an individual's life starts from an infant's first babble and is transformed into fully developed speech by the age of five.[7] The first stage of speech doesn't occur until around age one (holophrastic phase). Between the ages of one and a half and two and a half the infant can produce short sentences (telegraphic phase). After two and a half years the infant develops systems of lemmas used in speech production. Around four or five the child's lemmas are largely increased, this enhances the child's production of correct speech and they can now produce speech like an adult. An adult now develops speech in four stages: Activation of lexical concepts, select lemmas needed, morphologically and phonologically encode speech, and the word is phonetically encoded.[7]
Three stages
The production of spoken language involves three major levels of processing: conceptualization, formulation, and articulation.[1][8][9]
The first is the processes of conceptualization or conceptual preparation, in which the intention to create speech links a desired concept to the particular spoken words to be expressed. Here the preverbal intended messages are formulated that specify the concepts to be expressed.[10]
The second stage is formulation in which the linguistic form required for the expression of the desired message is created. Formulation includes grammatical encoding, morpho-phonological encoding, and phonetic encoding.[10] Grammatical encoding is the process of selecting the appropriate syntactic word or lemma. The selected lemma then activates the appropriate syntactic frame for the conceptualized message. Morpho-phonological encoding is the process of breaking words down into syllables to be produced in overt speech. Syllabification is dependent on the preceding and proceeding words, for instance: I-com-pre-hend vs. I-com-pre-hen-dit.[10] The final part of the formulation stage is phonetic encoding. This involves the activation of articulatory gestures dependent on the syllables selected in the morpho-phonological process, creating an articulatory score as the utterance is pieced together and the order of movements of the vocal apparatus is completed.[10]
The third stage of speech production is articulation, which is the execution of the articulatory score by the lungs, glottis, larynx, tongue, lips, jaw and other parts of the vocal apparatus resulting in speech.[8][10]

Neuroscience
The motor control for speech production in right handed people depends mostly upon areas in the left cerebral hemisphere. These areas include the bilateral supplementary motor area, the left posterior inferior frontal gyrus, the left insula, the left primary motor cortex and temporal cortex.[11] There are also subcortical areas involved such as the basal ganglia and cerebellum.[12][13] The cerebellum aids the sequencing of speech syllables into fast, smooth and rhythmically organized words and longer utterances.[13]
Disorders
Speech production can be affected by several disorders:
History of speech production research
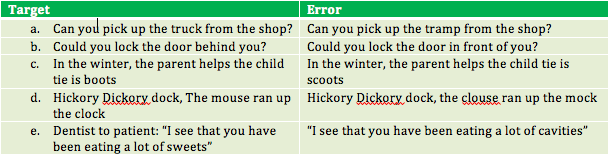
Until the late 1960s research on speech was focused on comprehension. As researchers collected greater volumes of speech error data, they began to investigate the psychological processes responsible for the production of speech sounds and to contemplate possible processes for fluent speech.[14] Findings from speech error research were soon incorporated into speech production models. Evidence from speech error data supports the following conclusions about speech production.
Some of these ideas include:
- Speech is planned in advance.[15]
- The lexicon is organized both semantically and phonologically.[15] That is by meaning, and by the sound of the words.
- Morphologically complex words are assembled.[15] Words that we produce that contain morphemes are put together during the speech production process. Morphemes are the smallest units of language that contain meaning. For example, "ed" on a past tense word.
- Affixes and functors behave differently from context words in slips of the tongue.[15] This means the rules about the ways in which a word can be used are likely stored with them, which means generally when speech errors are made, the mistake words maintain their functions and make grammatical sense.
- Speech errors reflect rule knowledge.[15] Even in our mistakes, speech is not nonsensical. The words and sentences that are produced in speech errors are typically grammatical, and do not violate the rules of the language being spoken.
Aspects of speech production models
Models of speech production must contain specific elements to be viable. These include the elements from which speech is composed, listed below. The accepted models of speech production discussed in more detail below all incorporate these stages either explicitly or implicitly, and the ones that are now outdated or disputed have been criticized for overlooking one or more of the following stages.[16]
The attributes of accepted speech models are:
a) a conceptual stage where the speaker abstractly identifies what they wish to express.[16]
b) a syntactic stage where a frame is chosen that words will be placed into, this frame is usually sentence structure.[16]
c) a lexical stage where a search for a word occurs based on meaning. Once the word is selected and retrieved, information about it becomes available to the speaker involving phonology and morphology.[16]
d) a phonological stage where the abstract information is converted into a speech like form.[16]
e) a phonetic stage where instructions are prepared to be sent to the muscles of articulation.[16]
Also, models must allow for forward planning mechanisms, a buffer, and a monitoring mechanism.
Following are a few of the influential models of speech production that account for or incorporate the previously mentioned stages and include information discovered as a result of speech error studies and other disfluency data,[17] such as tip-of-the-tongue research.
Models
The Utterance Generator Model (1971)
The Utterance Generator Model was proposed by Fromkin (1971).[18] It is composed of six stages and was an attempt to account for the previous findings of speech error research. The stages of the Utterance Generator Model were based on possible changes in representations of a particular utterance. The first stage is where a person generates the meaning they wish to convey. The second stage involves the message being translated onto a syntactic structure. Here, the message is given an outline.[19] The third stage proposed by Fromkin is where/when the message gains different stresses and intonations based on the meaning. The fourth stage Fromkin suggested is concerned with the selection of words from the lexicon. After the words have been selected in Stage 4, the message undergoes phonological specification.[20] The fifth stage applies rules of pronunciation and produces syllables that are to be outputted. The sixth and final stage of Fromkin's Utterance Generator Model is the coordination of the motor commands necessary for speech. Here, phonetic features of the message are sent to the relevant muscles of the vocal tract so that the intended message can be produced. Despite the ingenuity of Fromkin's model, researchers have criticized this interpretation of speech production. Although The Utterance Generator Model accounts for many nuances and data found by speech error studies, researchers decided it still had room to be improved.[21][22]
The Garrett model (1975)
A more recent (than Fromkin's) attempt to explain speech production was published by Garrett in 1975.[23] Garrett also created this model by compiling speech error data and there are many overlaps between this model and the Fromkin model off which it was based, but he did add a few things to the Fromkin model that filled some of the gaps being pointed out by other researchers. The Garrett Model and the Fromkin model both distinguish between three levels—a conceptual level, and sentence level, and a motor level. These three levels are common to contemporary understanding of Speech Production.[24]
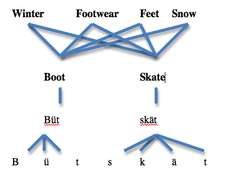
Dell's model (1994)
In 1994,[25] Dell proposed a model of the lexical network that became fundamental in the understanding of the way speech is produced.[1] This model of the lexical network attempts to symbolically represent the lexicon, and in turn, explain how people choose the words they wish to produce, and how those words are to be organized into speech. Dell's model was composed of three stages, semantics, words, and phonemes. The words in the highest stage of the model represent the semantic category. (In the image, the words representing semantic category are winter, footwear, feet, and snow represent the semantic categories of boot and skate.) The second level represents the words that describe the semantic category (In the image, boot and skate). And, the third level represents the phonemes ( syllabic information including onset, vowels, and codas).[26]
Levelt model (1999)
Levelt further refined the lexical network proposed by Dell. Through the use of speech error data, Levelt recreated the three levels in Dell's model. The conceptual stratum, the top and most abstract level, contains information a person has about ideas of particular concepts.[27] The conceptual stratum also contains ideas about how concepts relate to each other. This is where word selection would occur, a person would choose which words they wish to express. The next, or middle level, the lemma-stratum, contains information about the syntactic functions of individual words including tense and function.[1] This level functions to maintain syntax and place words correctly into sentence structure that makes sense to the speaker.[27] The lowest and final level is the form stratum which, similarly to the Dell Model, contains syllabic information. From here, the information stored at the form stratum level is sent to the motor cortex where the vocal apparatus are coordinated to physically produce speech sounds.
Places of articulation
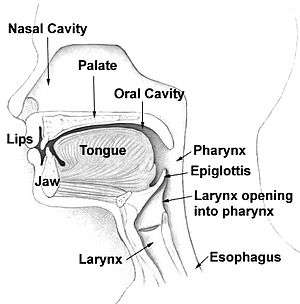
The physical structure of the human nose, throat, and vocal chords allows for the productions of many unique sounds, these areas can be further broken down into places of articulation. Different sounds are produced in different areas, and with different muscles and breathing techniques.[28] Our ability to utilize these skills to create the various sounds needed to communicate effectively is essential to our speech production. Difficulties in manner of articulation can contribute to speech difficulties and impediments.[29] It is suggested that infants are capable of making the entire spectrum of possible vowel and consonant sounds. IPA has created a system for understanding and categorizing all possible speech sounds, which includes information about the way in which the sound is produced, and where the sounds is produced.[29] This is extremely useful in the understanding of speech production because speech can be transcribed based on sounds rather than spelling, which may be misleading depending on the language being spoken. However, as people grow accustomed to a particular language they lose not only the ability to produce certain speech sounds, but also to distinguish between these sounds.[29]
Articulation
Articulation, often associated with speech production, is the term used to describe how people physically produced speech sounds. For people who speak fluently, articulation is automatic and allows 15 speech sounds to be produced per minute.[30]
Development
Before even producing a sound, infants imitate facial expressions and movements.[31] Around 7 months of age, infants start to experiment with communicative sounds by trying to coordinate producing sound with opening and closing their mouths.
Until the first year of life infants cannot produce coherent words, instead they produce a reoccurring babbling sound. Babbling allows the infant to experiment with articulating sounds without having to attend to meaning. This repeated babbling starts the initial production of speech. Babbling works with object permanence and understanding of location to support the networks of our first lexical items or words.[7] The infant’s vocabulary growth increases substantially when they are able to understand that objects exist even when they are not present.
The first stage of meaningful speech does not occur until around the age of one. This stage is the holophrastic phase.[32] The holistic stage refers to when infant speech consists of one word at a time (i.e. papa).
The next stage is the telegraphic phase. In this stage infants can form short sentences (i.e., Daddy sit, or Mommy drink). This typically occurs between the ages of one and a half and two and a half years old. This stage is particularly noteworthy because of the explosive growth of their lexicon. During this stage, infants must select and match stored representations of words to the specific perceptual target word in order to convey meaning or concepts.[31] With enough vocabulary, infants begin to extract sound patterns, and they learn to break down words into phonological segments, increasing further the number of words they can learn.[7] At this point in an infant's development of speech their lexicon consists of 200 words or more and they are able to understand even more than they can speak.[32]
When they reach two and a half years their speech production becomes increasingly complex, particularly in its semantic structure. With a more detailed semantic network the infant learns to express a wider range of meanings, helping the infant develop a complex conceptual system of lemmas.
Around the age of four or five the child lemmas have a wide range of diversity, this helps them select the right lemma needed to produce correct speech.[7] Reading to infants enhances their lexicon. At this age, children who have been read to and are exposed to more uncommon and complex words have 32 million more words than a child who is linguistically impoverished.[33] At this age the child should be able to speak in full complete sentences, similar to an adult.
See also
- FOXP2
- KE family
- Neurocomputational speech processing
- Psycholinguistics
- Silent speech interface
- Speech perception
- Speech science
References
- 1 2 3 4 Levelt, WJ (1999). "Models of word production." (PDF). Trends in Cognitive Sciences. 3 (6): 223–232. doi:10.1016/S1364-6613(99)01319-4. PMID 10354575.
- ↑ Garnham, A, Shillcock RC, Brown GDA, Mill AID, Culter A (1981). "Slips of the tongue in the London–Lund corpus of spontaneous conversation" (PDF). Linguistics. 19 (7–8): 805–817. doi:10.1515/ling.1981.19.7-8.805.
- ↑ Oldfield RC, Wingfield A (1965). "Response latencies in naming objects". Quarterly Journal of Experimental Psychology. 17 (4): 273–281. doi:10.1080/17470216508416445. PMID 5852918.
- ↑ Bird, H; Franklin, S; Howard, D (2001). "Age of acquisition and imageability ratings for a large set of words, including verbs and function words" (PDF). Behavior Research Methods, Instruments, and Computers. 33 (1): 73–9. doi:10.3758/BF03195349. PMID 11296722.
- ↑ Weinberg, B; Westerhouse, J (1971). "A study of buccal speech". Journal of Speech and Hearing Research. 14 (3): 652–8. Bibcode:1972ASAJ...51Q..91W. doi:10.1121/1.1981697. PMID 5163900.
- ↑ McNeill D (2005). Gesture and Thought. University of Chicago Press. ISBN 978-0-226-51463-5.
- 1 2 3 4 5 Harley, T.A. (2011), Psycholinguistics. (Volume 1). SAGE Publications.
- 1 2 Levelt, WJM (1989). Speaking: From Intention to Articulation. MIT Press. ISBN 978-0-262-62089-5.
- ↑ Jescheniak, JD; Levelt, WJM (1994). "Word frequency effects in speech production: retrieval of syntactic information and of phonological form". Journal of Experimental Psychology: Learning, Memory, and Cognition. 20 (4): 824–843. CiteSeerX 10.1.1.133.3919
 . doi:10.1037/0278-7393.20.4.824.
. doi:10.1037/0278-7393.20.4.824. - 1 2 3 4 5 Levelt, W. (1999). "The neurocognition of language", p.87 -117. Oxford Press
- ↑ Indefrey, P; Levelt, WJ (2004). "The spatial and temporal signatures of word production components". Cognition. 92 (1–2): 101–44. doi:10.1016/j.cognition.2002.06.001. PMID 15037128.
- ↑ Booth, JR; Wood, L; Lu, D; Houk, JC; Bitan, T (2007). "The role of the basal ganglia and cerebellum in language processing". Brain Research. 1133 (1): 136–44. doi:10.1016/j.brainres.2006.11.074. PMC 2424405. PMID 17189619.
- 1 2 Ackermann, H (2008). "Cerebellar contributions to speech production and speech perception: psycholinguistic and neurobiological perspectives". Trends in Neurosciences. 31 (6): 265–72. doi:10.1016/j.tins.2008.02.011. PMID 18471906.
- ↑ Fromkin, Victoria; Bernstein, Nan (1998). Speech Production Processing Models. Harcourt Brace College. p. 327. ISBN 0155041061.
- 1 2 3 4 5 Fromkin, Victoria; Berstien Ratner, Nan. Chapter 7 Speech Production. Harcourt Brace College. pp. 322–327. ISBN 0155041061.
- 1 2 3 4 5 6 Field, John (2004). Psycholinguistics. Routledge. p. 284. ISBN 0415258901.
- ↑ Fromkin, Victoria; Berstein, Nan. Speech Production Processing Models. p. 328. ISBN 0155041061.
- ↑ Fromkin, Victoria; Bernstein Ratner, Nan (1998). Chapter 7 Speech Production (Second ed.). Florida: Harcourt Brace College Publishers. pp. 328–337. ISBN 0155041061.
- ↑ Fromkin, Victoria (1971). Utterance Generator Model of Speech Production in Psycho-linguistics (2 ed.). Harcourt College Publishers. p. 328. ISBN 0155041061.
- ↑ Fromkin, Victoria (1998). Utterance Generator Model of Speech Production in Psycho-linguistics (2 ed.). Harcourt. p. 330.
- ↑ Garrett (1975). The Garrett Model in Psycho-linguistics. Harcourt College. p. 331. ISBN 0155041061.
- ↑ Butterworth (1982). Psycho-linguistics. Harcourt College. p. 331.
- ↑ Fromkin, Victoria; Berstein, Nan (1998). The Garret Model in Psycho-linguistics. Harcourt College. p. 331. ISBN 0155041061.
- ↑ Garrett; Fromkin, V.A.; Ratner, N.B (1998). The Garrett Model in Psycho-linguistics. Harcourt College. p. 331.
- ↑ "Psycholinguistics/Models of Speech Production - Wikiversity". en.wikiversity.org. Retrieved 2015-11-16.
- ↑ Dell, G.S. (1997). "Analysis of Sentence Production". Psychology of Learning and Motivation: 133–177. doi:10.1016/S0079-7421(08)60270-4.
- 1 2 Levelt, Willem J.M (1999). "Models of Word Production". Trends in Cognitive Sciences. 3: 223–232. doi:10.1016/S1364-6613(99)01319-4. PMID 10354575. Retrieved 25 October 2015.
- ↑ Keren, Rice (2011). Consonantal Place of Articulation. John Wily & Sons Inc. pp. 519–549. ISBN 978-1-4443-3526-2.
- 1 2 3 Harrison, Allen. E (2011). Speech Disorders : Causes, Treatments, and Social Effects. New York: Nova Science Publishers. ISBN 9781608762132.
- ↑ Field, John (2004). Psycholinguistics The Key Concepts. Routledge. pp. 18–19. ISBN 0415258901.
- 1 2 Redford, M. A. (2015). The handbook of speech production. Chichester, West Sussex ; Malden, MA : John Wiley & Sons, Ltd, 2015.
- 1 2 Shaffer, D., Wood, E., & Willoughby, T. (2005). Developmental Psychology Childhood and Adolescence. (2nd Canadian Ed). Nelson.
- ↑ Wolf, M. (2005). Proust and the squid:The story and science of the reading brain, New York, NY. Harper
Further reading
- Gow DW (June 2012). "The cortical organization of lexical knowledge: a dual lexicon model of spoken language processing". Brain Lang. 121 (3): 273–88. doi:10.1016/j.bandl.2012.03.005. PMC 3348354. PMID 22498237.
- Hickok G (2012). "The cortical organization of speech processing: feedback control and predictive coding the context of a dual-stream model". J Commun Disord. 45 (6): 393–402. doi:10.1016/j.jcomdis.2012.06.004. PMC 3468690. PMID 22766458.
- Hickok G, Houde J, Rong F (February 2011). "Sensorimotor integration in speech processing: computational basis and neural organization". Neuron. 69 (3): 407–22. doi:10.1016/j.neuron.2011.01.019. PMC 3057382. PMID 21315253.
- Hickok G, Poeppel D (2004). "Dorsal and ventral streams: a framework for understanding aspects of the functional anatomy of language". Cognition. 92 (1-2): 67–99. doi:10.1016/j.cognition.2003.10.011. PMID 15037127.
- Poeppel D, Emmorey K, Hickok G, Pylkkänen L (October 2012). "Towards a new neurobiology of language". J. Neurosci. 32 (41): 14125–31. doi:10.1523/JNEUROSCI.3244-12.2012. PMC 3495005. PMID 23055482.
- Price CJ (August 2012). "A review and synthesis of the first 20 years of PET and fMRI studies of heard speech, spoken language and reading". NeuroImage. 62 (2): 816–47. doi:10.1016/j.neuroimage.2012.04.062. PMC 3398395. PMID 22584224.
- Stout D, Chaminade T (January 2012). "Stone tools, language and the brain in human evolution". Philos. Trans. R. Soc. Lond., B, Biol. Sci. 367 (1585): 75–87. doi:10.1098/rstb.2011.0099. PMC 3223784. PMID 22106428.