Multiple comparisons problem
In statistics, the multiple comparisons, multiplicity or multiple testing problem occurs when one considers a set of statistical inferences simultaneously[1] or infers a subset of parameters selected based on the observed values.[2] It is also known as the look-elsewhere effect.
Errors in inference, including confidence intervals that fail to include their corresponding population parameters or hypothesis tests that incorrectly reject the null hypothesis, are more likely to occur when one considers the set as a whole. Several statistical techniques have been developed to prevent this from happening, allowing significance levels for single and multiple comparisons to be directly compared. These techniques generally require a higher significance threshold for individual comparisons, so as to compensate for the number of inferences being made.
History
The interest in the problem of multiple comparisons began in the 1950s with the work of Tukey and Scheffé. New methods and procedures came out: the closed testing procedure (Marcus et al., 1976) and the Holm–Bonferroni method (1979). In 1995 work on the false discovery rate began. In 1996 the first conference on multiple comparisons took place in Israel. This was followed by conferences around the world, usually taking place about every two years.[3]
Definition
In this context the term "comparisons" refers to comparisons of two groups, such as a treatment group and a control group. "Multiple comparisons" arise when a statistical analysis encompasses a number of formal comparisons, with the presumption that attention will focus on the strongest differences among all comparisons that are made. Failure to compensate for multiple comparisons can have important real-world consequences, as illustrated by the following examples.
- Suppose the treatment is a new way of teaching writing to students, and the control is the standard way of teaching writing. Students in the two groups can be compared in terms of grammar, spelling, organization, content, and so on. As more attributes are compared, it becomes more likely that the treatment and control groups will appear to differ on at least one attribute by random chance alone.
- Suppose we consider the efficacy of a drug in terms of the reduction of any one of a number of disease symptoms. As more symptoms are considered, it becomes more likely that the drug will appear to be an improvement over existing drugs in terms of at least one symptom.
- Suppose we consider the safety of a drug in terms of the occurrences of different types of side effects. As more types of side effects are considered, it becomes more likely that the new drug will appear to be less safe than existing drugs in terms of at least one side effect.
In all three examples, as the number of comparisons increases, it becomes more likely that the groups being compared will appear to differ in terms of at least one attribute. Our confidence that a result will generalize to independent data should generally be weaker if it is observed as part of an analysis that involves multiple comparisons, rather than an analysis that involves only a single comparison.
For example, if one test is performed at the 5% level, there is only a 5% chance of incorrectly rejecting the null hypothesis if the null hypothesis is true. However, for 100 tests where all null hypotheses are true, the expected number of incorrect rejections is 5. If the tests are independent, the probability of at least one incorrect rejection is 99.4%. These errors are called false positives or Type I errors.
The problem also occurs for confidence intervals. Note that a single confidence interval with 95% coverage probability level will likely contain the population parameter it is meant to contain, i.e. in the long run 95% of confidence intervals built in that way will contain the true population parameter. However, if one considers 100 confidence intervals simultaneously, with coverage probability 0.95 each, it is highly likely that at least one interval will not contain its population parameter. The expected number of such non-covering intervals is 5, and if the intervals are independent, the probability that at least one interval does not contain the population parameter is 99.4%.
Techniques have been developed to control the false positive error rate associated with performing multiple statistical tests. Similarly, techniques have been developed to adjust confidence intervals so that the probability of at least one of the intervals not covering its target value is controlled.
Classification of multiple hypothesis tests
The following table defines the possible outcomes when testing multiple null hypotheses. Suppose we have a number m of null hypotheses, denoted by: H1, H2, ..., Hm. Using a statistical test, we reject the null hypothesis if the test is declared significant. We do not reject the null hypothesis if the test is non-significant. Summing each type of outcome over all Hi yields the following random variables:
| Null hypothesis is true (H0) | Alternative hypothesis is true (HA) | Total | |
|---|---|---|---|
| Test is declared significant | |||
| Test is declared non-significant | |||
| Total |









- is the total number hypotheses tested
- is the number of true null hypotheses, an unknown parameter
- is the number of true alternative hypotheses
- is the number of false positives (Type I error) (also called "false discoveries")
- is the number of true positives (also called "true discoveries")
- is the number of false negatives (Type II error)
- is the number of true negatives
- is the number of rejected null hypotheses (also called "discoveries", either true or false)

In hypothesis tests of which are true null hypotheses, is an observable random variable, and , , , and are unobservable random variables.
Example
For example, one might declare that a coin was biased if in 10 flips it landed heads at least 9 times. Indeed, if one assumes as a null hypothesis that the coin is fair, then the probability that a fair coin would come up heads at least 9 out of 10 times is (10 + 1) × (1/2)10 = 0.0107. This is relatively unlikely, and under statistical criteria such as p-value < 0.05, one would declare that the null hypothesis should be rejected — i.e., the coin is unfair.
A multiple-comparisons problem arises if one wanted to use this test (which is appropriate for testing the fairness of a single coin), to test the fairness of many coins. Imagine if one were to test 100 fair coins by this method. Given that the probability of a fair coin coming up 9 or 10 heads in 10 flips is 0.0107, one would expect that in flipping 100 fair coins ten times each, to see a particular (i.e., pre-selected) coin comes up heads 9 or 10 times would still be very unlikely, but seeing any coin behave that way, without concern for which one, would be quite probable. Precisely, the likelihood that all 100 fair coins are identified as fair by this criterion is (1 − 0.0107)100 ≈ 0.34. Therefore, the application of our single-test coin-fairness criterion to multiple comparisons would be more likely to falsely identify at least one fair coin as unfair.
Controlling procedures
For hypothesis testing, the problem of multiple comparisons (also known as the multiple testing problem) results from the increase in type I error that occurs when statistical tests are used repeatedly. If k independent comparisons are performed, the experiment-wide significance level , also termed family-wise error rate (FWER), is given by


Hence, unless the tests are perfectly positively dependent, increases as the number of comparisons increases. If we do not assume that the comparisons are independent, then we can still say:

which follows from Boole's inequality. Example:

There are different ways to assure that the family-wise error rate is at most . The most conservative method, which is free of dependence and distributional assumptions, is the Bonferroni correction .

A marginally less conservative correction can be obtained by solving the equation for the family-wise error rate of independent comparisons for . This yields , which is known as the Šidák correction. Another procedure is the Holm–Bonferroni method, which uniformly delivers more power than the simple Bonferroni correction, by testing only the lowest p-value () against the strictest criterion, and the higher p-values () against progressively less strict criteria.[4] .






Multiple testing correction refers to re-calculating probabilities obtained from a statistical test which was repeated multiple times. In order to retain a prescribed family-wise error rate α in an analysis involving more than one comparison, the error rate for each comparison must be more stringent than α. Boole's inequality implies that if each of k tests is performed to have type I error rate α/k, the total error rate will not exceed α. This is called the Bonferroni correction, and is one of the most commonly used approaches for multiple comparisons.
In some situations, the Bonferroni correction is substantially conservative, i.e., the actual family-wise error rate is much less than the prescribed level α. This occurs when the test statistics are highly dependent (in the extreme case where the tests are perfectly dependent, the family-wise error rate with no multiple comparisons adjustment and the per-test error rates are identical). For example, in fMRI analysis,[5][6] tests are done on over 100,000 voxels in the brain. The Bonferroni method would require p-values to be smaller than .05/100000 to declare significance. Since adjacent voxels tend to be highly correlated, this threshold is generally too stringent.
Because simple techniques such as the Bonferroni method can be conservative, there has been a great deal of attention paid to developing better techniques, such that the overall rate of false positives can be maintained without excessively inflating the rate of false negatives. Such methods can be divided into general categories:
- Methods where total alpha can be proved to never exceed 0.05 (or some other chosen value) under any conditions. These methods provide "strong" control against Type I error, in all conditions including a partially correct null hypothesis.
- Methods where total alpha can be proved not to exceed 0.05 except under certain defined conditions.
- Methods which rely on an omnibus test before proceeding to multiple comparisons. Typically these methods require a significant ANOVA/Tukey's range test before proceeding to multiple comparisons. These methods have "weak" control of Type I error.
- Empirical methods, which control the proportion of Type I errors adaptively, utilizing correlation and distribution characteristics of the observed data.
The advent of computerized resampling methods, such as bootstrapping and Monte Carlo simulations, has given rise to many techniques in the latter category. In some cases where exhaustive permutation resampling is performed, these tests provide exact, strong control of Type I error rates; in other cases, such as bootstrap sampling, they provide only approximate control.
Large-scale multiple testing
Traditional methods for multiple comparisons adjustments focus on correcting for modest numbers of comparisons, often in an analysis of variance. A different set of techniques have been developed for "large-scale multiple testing", in which thousands or even greater numbers of tests are performed. For example, in genomics, when using technologies such as microarrays, expression levels of tens of thousands of genes can be measured, and genotypes for millions of genetic markers can be measured. Particularly in the field of genetic association studies, there has been a serious problem with non-replication — a result being strongly statistically significant in one study but failing to be replicated in a follow-up study. Such non-replication can have many causes, but it is widely considered that failure to fully account for the consequences of making multiple comparisons is one of the causes.[7]
In different branches of science, multiple testing is handled in different ways. It has been argued that if statistical tests are only performed when there is a strong basis for expecting the result to be true, multiple comparisons adjustments are not necessary.[8] It has also been argued that use of multiple testing corrections is an inefficient way to perform empirical research, since multiple testing adjustments control false positives at the potential expense of many more false negatives. On the other hand, it has been argued that advances in measurement and information technology have made it far easier to generate large datasets for exploratory analysis, often leading to the testing of large numbers of hypotheses with no prior basis for expecting many of the hypotheses to be true. In this situation, very high false positive rates are expected unless multiple comparisons adjustments are made.[9]
For large-scale testing problems where the goal is to provide definitive results, the familywise error rate remains the most accepted parameter for ascribing significance levels to statistical tests. Alternatively, if a study is viewed as exploratory, or if significant results can be easily re-tested in an independent study, control of the false discovery rate (FDR)[10][11][12] is often preferred. The FDR, defined as the expected proportion of false positives among all significant tests, allows researchers to identify a set of "candidate positives", of which a high proportion are likely to be true. The false positives within the candidate set can then be identified in a follow-up study.[13]
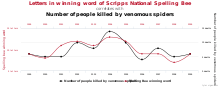
The practice of trying many unadjusted comparisons in the hope of finding a significant one is a known problem, whether applied unintentionally or deliberately.[14] It is known as data dredging or p-hacking.[15][16]
Assessing whether any alternative hypotheses are true

A basic question faced at the outset of analyzing a large set of testing results is whether there is evidence that any of the alternative hypotheses are true. One simple meta-test that can be applied when it is assumed that the tests are independent of each other is to use the Poisson distribution as a model for the number of significant results at a given level α that would be found when all null hypotheses are true. If the observed number of positives is substantially greater than what should be expected, this suggests that there are likely to be some true positives among the significant results. For example, if 1000 independent tests are performed, each at level α = 0.05, we expect 50 significant tests to occur when all null hypotheses are true. Based on the Poisson distribution with mean 50, the probability of observing more than 61 significant tests is less than 0.05, so if more than 61 significant results are observed, it is very likely that some of them correspond to situations where the alternative hypothesis holds. A drawback of this approach is that it over-states the evidence that some of the alternative hypotheses are true when the test statistics are positively correlated, which commonly occurs in practice. . On the other hand, the approach remains valid even in the presence of correlation among the test statistics, as long as the Poisson distribution can be shown to provide a good approximation for the number of significant results. This scenario arises, for instance, when mining significant frequent itemsets from transactional datasets. Furthermore, a careful two stage analysis can bound the FDR at a pre-specified level.[17]
Another common approach that can be used in situations where the test statistics can be standardized to Z-scores is to make a normal quantile plot of the test statistics. If the observed quantiles are markedly more dispersed than the normal quantiles, this suggests that some of the significant results may be true positives.
See also
- Key concepts
- Familywise error rate
- False positive rate
- False discovery rate (FDR)
- False coverage rate (FCR)
- Interval estimation
- Post-hoc analysis
- Experimentwise error rate
- General methods of alpha adjustment for multiple comparisons
- Related concepts
References
- ↑ Miller, R.G. (1981). Simultaneous Statistical Inference 2nd Ed. Springer Verlag New York. ISBN 0-387-90548-0.
- ↑ Benjamini, Y. (2010). "Simultaneous and selective inference: Current successes and future challenges". Biometrical Journal. 52 (6): 708–721. doi:10.1002/bimj.200900299. PMID 21154895.
- ↑
- ↑ Aickin, M; Gensler, H (May 1996). "Adjusting for multiple testing when reporting research results: the Bonferroni vs Holm methods". Am J Public Health. 1996 (86): 726–728. doi:10.2105/ajph.86.5.726. PMC 1380484
 . PMID 8629727.
. PMID 8629727. - ↑ Logan, B. R.; Rowe, D. B. (2004). "An evaluation of thresholding techniques in fMRI analysis". NeuroImage. 22 (1): 95–108. doi:10.1016/j.neuroimage.2003.12.047. PMID 15110000.
- ↑ Logan, B. R.; Geliazkova, M. P.; Rowe, D. B. (2008). "An evaluation of spatial thresholding techniques in fMRI analysis". Human Brain Mapping. 29 (12): 1379–1389. doi:10.1002/hbm.20471. PMID 18064589.
- ↑ Qu, Hui-Qi; Tien, Matthew; Polychronakos, Constantin (2010-10-01). "Statistical significance in genetic association studies". Clinical and Investigative Medicine. Medecine Clinique et Experimentale. 33 (5): E266–E270. ISSN 0147-958X. PMC 3270946. PMID 20926032.
- ↑ Rothman, Kenneth J. (1990). "No Adjustments Are Needed for Multiple Comparisons". Epidemiology. Lippincott Williams & Wilkins. 1 (1): 43–46. doi:10.1097/00001648-199001000-00010. JSTOR 20065622. PMID 2081237.
- ↑ Ioannidis, JPA (2005). "Why Most Published Research Findings Are False". PLoS Med. 2 (8): e124. doi:10.1371/journal.pmed.0020124. PMC 1182327. PMID 16060722.
- ↑ Benjamini, Yoav; Hochberg, Yosef (1995). "Controlling the false discovery rate: a practical and powerful approach to multiple testing". Journal of the Royal Statistical Society, Series B. 57 (1): 125–133. JSTOR 2346101.
- ↑ Storey, JD; Tibshirani, Robert (2003). "Statistical significance for genome-wide studies". PNAS. 100 (16): 9440–9445. doi:10.1073/pnas.1530509100. JSTOR 3144228. PMC 170937. PMID 12883005.
- ↑ Efron, Bradley; Tibshirani, Robert; Storey, John D.; Tusher,Virginia (2001). "Empirical Bayes analysis of a microarray experiment". Journal of the American Statistical Association. 96 (456): 1151–1160. doi:10.1198/016214501753382129. JSTOR 3085878.
- ↑ Noble, William S. (2009-12-01). "How does multiple testing correction work?". Nature Biotechnology. 27 (12): 1135–1137. doi:10.1038/nbt1209-1135. ISSN 1087-0156. PMC 2907892. PMID 20010596.
- ↑ Young, S. S., Karr, A. (2011). "Deming, data and observational studies" (PDF). Significance. 8 (3).
- ↑ Smith, G. D., Shah, E. (2002). "Data dredging, bias, or confounding". BMJ. 325 (7378): 1437–1438. doi:10.1136/bmj.325.7378.1437. PMC 1124898. PMID 12493654.
- ↑ Bohannon, John. "I Fooled Millions Into Thinking Chocolate Helps Weight Loss. Here's How.". io9. Gawker Media. Retrieved 5 April 2016.
- ↑ Kirsch, A; Mitzenmacher, M; Pietracaprina, A; Pucci, G; Upfal, E; Vandin, F (June 2012). "An Efficient Rigorous Approach for Identifying Statistically Significant Frequent Itemsets". Journal of the ACM. 59 (3): 12:1–12:22. doi:10.1145/2220357.2220359.
Further reading
- F. Betz, T. Hothorn, P. Westfall (2010), Multiple Comparisons Using R, CRC Press
- S. Dudoit and M. J. van der Laan (2008), Multiple Testing Procedures with Application to Genomics, Springer
- B. Phipson and G. K. Smyth (2010), Permutation P-values Should Never Be Zero: Calculating Exact P-values when Permutations are Randomly Drawn, Statistical Applications in Genetics and Molecular Biology Vol.. 9 Iss. 1, Article 39, doi:10.2202/1544-6155.1585
- P. H. Westfall and S. S. Young (1993), Resampling-based Multiple Testing: Examples and Methods for p-Value Adjustment, Wiley
- P. Westfall, R. Tobias, R. Wolfinger (2011) Multiple comparisons and multiple testing using SAS, 2nd edn, SAS Institute
- A gallery of examples of implausible correlations sourced by data dredging
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||