Matrix multiplication

In mathematics, matrix multiplication or the matrix product is a binary operation that produces a matrix from two matrices. The definition is motivated by linear equations and linear transformations on vectors, which have numerous applications in applied mathematics, physics, and engineering.[1][2] In more detail, if A is an n × m matrix and B is an m × p matrix, their matrix product AB is an n × p matrix, in which the m entries across a row of A are multiplied with the m entries down a columns of B and summed to produce an entry of AB. When two linear transformations are represented by matrices, then the matrix product represents the composition of the two transformations.
The matrix product is not commutative in general, although it is associative and is distributive over matrix addition. The identity element of the matrix product is the identity matrix (analogous to multiplying numbers by 1), and a square matrix may have an inverse matrix (analogous to the multiplicative inverse of a number). Determinant multiplicativity applies to the matrix product. The matrix product is also important for matrix groups, and the theory of group representations and irreps.
Computing matrix products is both a central operation in many numerical algorithms and potentially time consuming, making it one of the most well-studied problems in numerical computing. Various algorithms have been devised for computing C = AB, especially for large matrices.
Notation
This article will use the following notational conventions: matrices are represented by capital letters in bold, e.g. A, vectors in lowercase bold, e.g. a, and entries of vectors and matrices are italic (since they are numbers from a field), e.g. A and a. Index notation is often the clearest way to express definitions, and is used as standard in the literature. The i, j entry of matrix A is indicated by (A)ij or Aij, whereas a numerical label (not matrix entries) on a collection of matrices is subscripted only, e.g. A1, A2, etc.
Matrix product (two matrices)
Assume two matrices are to be multiplied (the generalization to any number is discussed below).
General definition of the matrix product
If A is an n × m matrix and B is an m × p matrix,

the matrix product AB (denoted without multiplication signs or dots) is defined to be the n × p matrix[3][4][5][6]

where each i, j entry is given by multiplying the entries Aik (across row i of A) by the entries Bkj (down column j of B), for k = 1, 2, ..., m, and summing the results over k:

Thus the product AB is defined only if the number of columns in A is equal to the number of rows in B, in this case m. Each entry may be computed one at a time. Sometimes, the summation convention is used as it is understood to sum over the repeated index k. To prevent any ambiguity, this convention will not be used in the article.
Usually the entries are numbers or expressions, but can even be matrices themselves (see block matrix). The matrix product can still be calculated exactly the same way. See below for details on how the matrix product can be calculated in terms of blocks taking the forms of rows and columns.
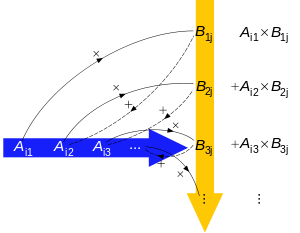
Illustration

The figure to the right illustrates diagrammatically the product of two matrices A and B, showing how each intersection in the product matrix corresponds to a row of A and a column of B.

The values at the intersections marked with circles are:

Examples of matrix products
Row vector and column vector
If

their matrix products are:

and

Note AB and BA are two different matrices: the first is a 1 × 1 matrix while the second is a 3 × 3 matrix. Such expressions occur for real-valued Euclidean vectors in Cartesian coordinates, displayed as row and column matrices, in which case AB is the matrix form of their dot product, while BA the matrix form of their dyadic or tensor product.
Square matrix and column vector
If

their matrix product is:

however BA is not defined.
The product of a square matrix multiplied by a column matrix arises naturally in linear algebra; for solving linear equations and representing linear transformations. By choosing a, b, c, p, q, r, u, v, w in A appropriately, A can represent a variety of transformations such as rotations, scaling and reflections, shears, of a geometric shape in space.
Square matrices
If

their matrix products are:

and

In this case, both products AB and BA are defined, and the entries show that AB and BA are not equal in general. Multiplying square matrices which represent linear transformations corresponds to the composite transformation (see below for details).
Row vector, square matrix, and column vector
If

their matrix product is:
![{\begin{aligned}\mathbf {ABC} &={\begin{pmatrix}a&b&c\end{pmatrix}}\left[{\begin{pmatrix}\alpha &\beta &\gamma \\\lambda &\mu &\nu \\\rho &\sigma &\tau \\\end{pmatrix}}{\begin{pmatrix}x\\y\\z\end{pmatrix}}\right]=\left[{\begin{pmatrix}a&b&c\end{pmatrix}}{\begin{pmatrix}\alpha &\beta &\gamma \\\lambda &\mu &\nu \\\rho &\sigma &\tau \\\end{pmatrix}}\right]{\begin{pmatrix}x\\y\\z\end{pmatrix}}\\&={\begin{pmatrix}a&b&c\end{pmatrix}}{\begin{pmatrix}\alpha x+\beta y+\gamma z\\\lambda x+\mu y+\nu z\\\rho x+\sigma y+\tau z\\\end{pmatrix}}={\begin{pmatrix}a\alpha +b\lambda +c\rho &a\beta +b\mu +c\sigma &a\gamma +b\nu +c\tau \end{pmatrix}}{\begin{pmatrix}x\\y\\z\end{pmatrix}}\\&=a\alpha x+b\lambda x+c\rho x+a\beta y+b\mu y+c\sigma y+a\gamma z+b\nu z+c\tau z\,,\end{aligned}}](../I/m/43c6d62200e683fe070d5e66e7e94d11ffdfad2d.svg)
however CBA is not defined. Note that A(BC) = (AB)C, this is one of many general properties listed below. Expressions of the form ABC occur when calculating the inner product of two vectors displayed as row and column vectors in an arbitrary coordinate system, and the metric tensor in these coordinates written as the square matrix.
Rectangular matrices
If

their matrix products are:

and

Properties of the matrix product (two matrices)
Analogous to numbers (elements of a field), matrices satisfy the following general properties, although there is one subtlety, due to the nature of matrix multiplication.[7][8]
All matrices
- Not commutative:
In general:
because AB and BA may not be simultaneously defined, and even if they are they may still not be equal. This is contrary to ordinary multiplication of numbers. To specify the ordering of matrix multiplication in words; "pre-multiply (or left multiply) A by B" means BA, while "post-multiply (or right multiply) A by C" means AC. As long as the entries of the matrix come from a ring that has an identity, and n > 1 there is a pair of n × n noncommuting matrices over the ring. A notable exception is that the identity matrix (or any scalar multiple of it) commutes with every square matrix.
In index notation:
- Distributive over matrix addition:
Left distributivity:
Right distributivity:
In index notation, these are respectively:
- Scalar multiplication is compatible with matrix multiplication:
- and
where λ is a scalar. If the entries of the matrix are real or complex numbers (or from any other commutative ring), then all four quantities are equal. More generally, all four are equal if λ belongs to the center of the ring of entries of the matrix, because in this case λX = Xλ for all matrices X. In index notation, these are respectively:
- Transpose:
where T denotes the transpose, the interchange of row i with column i in a matrix. This identity holds for any matrices over a commutative ring, but not for all rings in general. Note that A and B are reversed.
In index notation:
- Complex conjugate:
If A and B have complex entries, then
where * denotes the entry-wise complex conjugate of a matrix.
In index notation:
- Conjugate transpose:
If A and B have complex entries, then
where † denotes the Conjugate transpose of a matrix (complex conjugate and transposed).
In index notation:
- Traces:
The trace of a product AB is independent of the order of A and B:
In index notation:











![{\begin{aligned}\left[(\mathbf {AB} )^{\mathrm {T} }\right]_{ij}&=\left(\mathbf {AB} \right)_{ji}\\&=\sum _{k}\left(\mathbf {A} \right)_{jk}\left(\mathbf {B} \right)_{ki}\\&=\sum _{k}\left(\mathbf {A} ^{\mathrm {T} }\right)_{kj}\left(\mathbf {B} ^{\mathrm {T} }\right)_{ik}\\&=\sum _{k}\left(\mathbf {B} ^{\mathrm {T} }\right)_{ik}\left(\mathbf {A} ^{\mathrm {T} }\right)_{kj}\\&=\left[\left(\mathbf {B} ^{\mathrm {T} }\right)\left(\mathbf {A} ^{\mathrm {T} }\right)\right]_{ij}\end{aligned}}](../I/m/8bc6a19c27313397d4104044470bfbf1c7ab4476.svg)

![{\displaystyle {\begin{aligned}\left[(\mathbf {AB} )^{*}\right]_{ij}&=\left[\sum _{k}\left(\mathbf {A} \right)_{ik}\left(\mathbf {B} \right)_{kj}\right]^{*}\\&=\sum _{k}\left(\mathbf {A} \right)_{ik}^{*}\left(\mathbf {B} \right)_{kj}^{*}\\&=\sum _{k}\left(\mathbf {A} ^{*}\right)_{ik}\left(\mathbf {B} ^{*}\right)_{kj}\\&=\left(\mathbf {A} ^{*}\mathbf {B} ^{*}\right)_{ij}\end{aligned}}}](../I/m/5acef88f8f9bf382f9368bc351c5d0d0dcf5e764.svg)

![{\displaystyle {\begin{aligned}\left[(\mathbf {AB} )^{\dagger }\right]_{ij}&=\left[\left(\mathbf {AB} \right)^{*}\right]_{ji}\\&=\sum _{k}\left(\mathbf {A} ^{*}\right)_{jk}\left(\mathbf {B} ^{*}\right)_{ki}\\&=\sum _{k}\left(\mathbf {A} ^{\dagger }\right)_{kj}\left(\mathbf {B} ^{\dagger }\right)_{ik}\\&=\sum _{k}\left(\mathbf {B} ^{\dagger }\right)_{ik}\left(\mathbf {A} ^{\dagger }\right)_{kj}\\&=\left[\left(\mathbf {B} ^{\dagger }\right)\left(\mathbf {A} ^{\dagger }\right)\right]_{ij}\end{aligned}}}](../I/m/5895ee7019fd2ca6d6fc0458a4829b3728bb674d.svg)


Square matrices only
- Identity element:
If A is a square matrix, then
- Inverse matrix:
If A is a square matrix, there may be an inverse matrix A−1 of A such that
If this property holds then A is an invertible matrix, if not A is a singular matrix. Moreover,
- Determinants:
When a determinant of a matrix is defined (i.e., when the underlying ring is commutative), if A and B are square matrices of the same order, the determinant of their product AB equals the product of their determinants:




Matrix product (any number)
Matrix multiplication can be extended to the case of more than two matrices, provided that for each sequential pair, their dimensions match.
The product of n matrices A1, A2, ..., An with sizes s0 × s1, s1 × s2, ..., sn − 1 × sn (where s0, s1, s2, ..., sn are all simply positive integers and the subscripts are labels corresponding to the matrices, nothing more), is the s0 × sn matrix:

In index notation:

Properties of the matrix product (any number)
The same properties will hold, as long as the ordering of matrices is not changed. Some of the previous properties for more than two matrices generalize as follows.
- Associative:
The matrix product is associative. If three matrices A, B, and C are respectively m × p, p × q, and q × r matrices, then there are two ways of grouping them without changing their order, andis an m × r matrix.
If four matrices A, B, C, and D are respectively m × p, p × q, q × r, and r × s matrices, then there are five ways of grouping them without changing their order, andis an m × s matrix.
In general, the number of possible ways of grouping n matrices for multiplication is equal to the (n − 1)th Catalan number - Trace:
The trace of a product of n matrices A1, A2, ..., An is invariant under cyclic permutations of the matrices in the product:
- Determinant:
For square matrices only, the determinant of a product is the product of determinants:




Examples of chain multiplication
Similarity transformations involving similar matrices are matrix products of the three square matrices, in the form:

where P is the similarity matrix and A and B are said to be similar if this relation holds. This product appears frequently in linear algebra and applications, such as diagonalizing square matrices and the equivalence between different matrix representations of the same linear operator.
Operations derived from the matrix product
More operations on square matrices can be defined using the matrix product, such as powers and nth roots by repeated matrix products, the matrix exponential can be defined by a power series, the matrix logarithm is the inverse of matrix exponentiation, and so on.
Powers of matrices
Square matrices can be multiplied by themselves repeatedly in the same way as ordinary numbers, because they always have the same number of rows and columns. This repeated multiplication can be described as a power of the matrix, a special case of the ordinary matrix product. On the contrary, rectangular matrices do not have the same number of rows and columns so they can never be raised to a power. An n × n matrix A raised to a positive integer k is defined as

and the following identities hold, where λ is a scalar:
- Zero power:
- Scalar multiplication:
- Determinant:



The naive computation of matrix powers is to multiply k times the matrix A to the result, starting with the identity matrix just like the scalar case. This can be improved using exponentiation by squaring, a method commonly used for scalars. For diagonalizable matrices, an even better method is to use the eigenvalue decomposition of A. Another method based on the Cayley–Hamilton theorem finds an identity using the matrices' characteristic polynomial, producing a more effective equation for Ak in which a scalar is raised to the required power, rather than an entire matrix.
A special case is the power of a diagonal matrix. Since the product of diagonal matrices amounts to simply multiplying corresponding diagonal elements together, the power k of a diagonal matrix A will have entries raised to the power. Explicitly;

meaning it is easy to raise a diagonal matrix to a power. When raising an arbitrary matrix (not necessarily a diagonal matrix) to a power, it is often helpful to exploit this property by diagonalizing the matrix first.
Applications of the matrix product
Linear transformations
Matrices offer a concise way of representing linear transformations between vector spaces, and matrix multiplication corresponds to the composition of linear transformations. The matrix product of two matrices can be defined when their entries belong to the same ring, and hence can be added and multiplied.
Let U, V, and W be vector spaces over the same field with given bases, S: V → W and T: U → V be linear transformations and ST: U → W be their composition.
Suppose that A, B, and C are the matrices representing the transformations S, T, and ST with respect to the given bases.
Then AB = C, that is, the matrix of the composition (or the product) of linear transformations is the product of their matrices with respect to the given bases.
Linear systems of equations
A system of linear equations with the same number of equations as variables can be solved by collecting the coefficients of the equations into a square matrix, then inverting the matrix equation.
A similar procedure can be used to solve a system of linear differential equations, see also phase plane.
Group theory and representation theory
The inner and outer products
Given two column vectors a and b, the Euclidean inner product and outer product are the simplest special cases of the matrix product.[9]
Inner product
The inner product of two vectors in matrix form is equivalent to a column vector multiplied on its left by a row vector:

where aT denotes the transpose of a.
The matrix product itself can be expressed in terms of inner product. Suppose that the first n × m matrix A is decomposed into its row vectors ai, and the second m × p matrix B into its column vectors bi:[1]


where

Then:

It is also possible to express a matrix product in terms of concatenations of products of matrices and row or column vectors:

These decompositions are particularly useful for matrices that are envisioned as concatenations of particular types of row vectors or column vectors, e.g. orthogonal matrices (whose rows and columns are unit vectors orthogonal to each other) and Markov matrices (whose rows or columns sum to 1).
Outer product
The outer product (also known as the dyadic product or tensor product) of two vectors in matrix form is equivalent to a row vector multiplied on the left by a column vector:

An alternative method is to express the matrix product in terms of the outer product. The decomposition is done the other way around, the first matrix A is decomposed into column vectors ai and the second matrix B into row vectors bi:

where this time

This method emphasizes the effect of individual column/row pairs on the result, which is a useful point of view with e.g. covariance matrices, where each such pair corresponds to the effect of a single sample point.

Algorithms for efficient matrix multiplication

The running time of square matrix multiplication, if carried out naïvely, is O(n3). The running time for multiplying rectangular matrices (one m × p-matrix with one p × n-matrix) is O(mnp), however, more efficient algorithms exist, such as Strassen's algorithm, devised by Volker Strassen in 1969 and often referred to as "fast matrix multiplication". It is based on a way of multiplying two 2 × 2-matrices which requires only 7 multiplications (instead of the usual 8), at the expense of several additional addition and subtraction operations. Applying this recursively gives an algorithm with a multiplicative cost of . Strassen's algorithm is more complex, and the numerical stability is reduced compared to the naïve algorithm.[10] Nevertheless, it appears in several libraries, such as BLAS, where it is significantly more efficient for matrices with dimensions n > 100,[11] and is very useful for large matrices over exact domains such as finite fields, where numerical stability is not an issue.

The current O(nk) algorithm with the lowest known exponent k is a generalization of the Coppersmith–Winograd algorithm that has an asymptotic complexity of O(n2.3728639), by François Le Gall.[12] This algorithm, and the Coppersmith–Winograd algorithm on which it is based, are similar to Strassen's algorithm: a way is devised for multiplying two k × k-matrices with fewer than k3 multiplications, and this technique is applied recursively. However, the constant coefficient hidden by the Big O notation is so large that these algorithms are only worthwhile for matrices that are too large to handle on present-day computers.[13][14]
Since any algorithm for multiplying two n × n-matrices has to process all 2 × n2-entries, there is an asymptotic lower bound of Ω(n2) operations. Raz (2002) proves a lower bound of Ω(n2 log(n)) for bounded coefficient arithmetic circuits over the real or complex numbers.
Cohn et al. (2003, 2005) put methods such as the Strassen and Coppersmith–Winograd algorithms in an entirely different group-theoretic context, by utilising triples of subsets of finite groups which satisfy a disjointness property called the triple product property (TPP). They show that if families of wreath products of Abelian groups with symmetric groups realise families of subset triples with a simultaneous version of the TPP, then there are matrix multiplication algorithms with essentially quadratic complexity. Most researchers believe that this is indeed the case.[15] However, Alon, Shpilka and Chris Umans have recently shown that some of these conjectures implying fast matrix multiplication are incompatible with another plausible conjecture, the sunflower conjecture.[16]
Freivalds' algorithm is a simple Monte Carlo algorithm that given matrices A, B, C verifies in Θ(n2) time if AB = C.

Parallel matrix multiplication
Because of the nature of matrix operations and the layout of matrices in memory, it is typically possible to gain substantial performance gains through use of parallelization and vectorization. Several algorithms are possible, among which divide and conquer algorithms based on the block matrix decomposition

that also underlies Strassen's algorithm. Here, A, B and C are presumed to be n by n (square) matrices, and C11 etc. are n/2 by n/2 submatrices. From this decomposition, one derives[17]

which consists of eight multiplications of pairs of submatrices, which can all be performed in parallel, followed by an addition step. Applying this recursively, and performing the additions in parallel as well, one obtains an algorithm that runs in Θ(log2 n) time on an ideal machine with an infinite number of processors, and has a maximum possible speedup of Θ(n3/(log2 n)) on any real computer (although the algorithm isn't practical, a more practical variant achieves Θ(n2) speedup).[17]
It should be noted that some lower time-complexity algorithms on paper may have indirect time complexity costs on real machines.
Communication-avoiding and distributed algorithms
On modern architectures with hierarchical memory, the cost of loading and storing input matrix elements tends to dominate the cost of arithmetic. On a single machine this is the amount of data transferred between RAM and cache, while on a distributed memory multi-node machine it is the amount transferred between nodes; in either case it is called the communication bandwidth. The naïve algorithm using three nested loops uses Ω(n3) communication bandwidth.
Cannon's algorithm, also known as the 2D algorithm, partitions each input matrix into a block matrix whose elements are submatrices of size √M/3 by √M/3, where M is the size of fast memory.[18] The naïve algorithm is then used over the block matrices, computing products of submatrices entirely in fast memory. This reduces communication bandwidth to O(n3/√M), which is asymptotically optimal (for algorithms performing Ω(n3) computation).[19][20]
In a distributed setting with p processors arranged in a √p by √p 2D mesh, one submatrix of the result can be assigned to each processor, and the product can be computed with each processor transmitting O(n2/√p) words, which is asymptotically optimal assuming that each node stores the minimum O(n2/p) elements.[20] This can be improved by the 3D algorithm, which arranges the processors in a 3D cube mesh, assigning every product of two input submatrices to a single processor. The result submatrices are then generated by performing a reduction over each row.[21] This algorithm transmits O(n2/p2/3) words per processor, which is asymptotically optimal.[20] However, this requires replicating each input matrix element p1/3 times, and so requires a factor of p1/3 more memory than is needed to store the inputs. This algorithm can be combined with Strassen to further reduce runtime.[21] "2.5D" algorithms provide a continuous tradeoff between memory usage and communication bandwidth.[22] On modern distributed computing environments such as MapReduce, specialized multiplication algorithms have been developed.[23]
Other forms of multiplication
The term "matrix multiplication" is most commonly reserved for the definition given in this article. It could be more loosely applied to other definitions.
See also
| Wikimedia Commons has media related to matrix multiplication. |
Notes
- 1 2 Lerner, R. G.; Trigg, G. L. (1991). Encyclopaedia of Physics (2nd ed.). VHC publishers. ISBN 3-527-26954-1.
- ↑ Parker, C. B. (1994). McGraw Hill Encyclopaedia of Physics (2nd ed.). ISBN 0-07-051400-3.
- ↑ Lipschutz, S.; Lipson, M. (2009). Linear Algebra. Schaum's Outlines (4th ed.). McGraw Hill (USA). pp. 30–31. ISBN 978-0-07-154352-1.
- ↑ Riley, K. F.; Hobson, M. P.; Bence, S. J. (2010). Mathematical methods for physics and engineering. Cambridge University Press. ISBN 978-0-521-86153-3.
- ↑ Adams, R. A. (1995). Calculus, A Complete Course (3rd ed.). Addison Wesley. p. 627. ISBN 0 201 82823 5.
- ↑ Horn, Johnson (2013). Matrix Analysis (2nd ed.). Cambridge University Press. p. 6. ISBN 978 0 521 54823 6.
- ↑ Lipcshutz, S.; Lipson, M. (2009). "2". Linear Algebra. Schaum's Outlines (4th ed.). McGraw Hill (USA). ISBN 978-0-07-154352-1.
- ↑ Horn, Johnson (2013). "0". Matrix Analysis (2nd ed.). Cambridge University Press. ISBN 978 0 521 54823 6.
- ↑ Mathematical methods for physics and engineering, K.F. Riley, M.P. Hobson, S.J. Bence, Cambridge University Press, 2010, ISBN 978-0-521-86153-3
- ↑ Miller, Webb (1975), "Computational complexity and numerical stability", SIAM News, 4: 97–107, CiteSeerX 10.1.1.148.9947
 , doi:10.1137/0204009
, doi:10.1137/0204009 - ↑ Press 2007, p. 108.
- ↑ Le Gall, François (2014), "Powers of tensors and fast matrix multiplication", Proceedings of the 39th International Symposium on Symbolic and Algebraic Computation (ISSAC 2014), arXiv:1401.7714. The original algorithm was presented by Don Coppersmith and Shmuel Winograd in 1990, has an asymptotic complexity of O(n2.376). It was improved in 2013 to O(n2.3729) by Virginia Vassilevska Williams, giving a time only slightly worse than Le Gall's improvement: Williams, Virginia Vassilevska. "Multiplying matrices faster than Coppersmith-Winograd" (PDF).
- ↑ Iliopoulos, Costas S. (1989), "Worst-case complexity bounds on algorithms for computing the canonical structure of finite abelian groups and the Hermite and Smith normal forms of an integer matrix" (PDF), SIAM Journal on Computing, 18 (4): 658–669, doi:10.1137/0218045, MR 1004789,
The Coppersmith–Winograd algorithm is not practical, due to the very large hidden constant in the upper bound on the number of multiplications required.
- ↑ Robinson, Sara (2005), "Toward an Optimal Algorithm for Matrix Multiplication" (PDF), SIAM News, 38 (9)
- ↑ Robinson, 2005.
- ↑ Alon, Shpilka, Umans, On Sunflowers and Matrix Multiplication
- 1 2 Randall, Keith H. (1998). Cilk: Efficient Multithreaded Computing (PDF) (Ph.D.). Massachusetts Institute of Technology. pp. 54–57.
- ↑ Lynn Elliot Cannon, A cellular computer to implement the Kalman Filter Algorithm, Technical report, Ph.D. Thesis, Montana State University, 14 July 1969.
- ↑ Hong, J.W.; Kung, H. T. (1981). "I/O complexity: The red-blue pebble game". STOC ’81: Proceedings of the thirteenth annual ACM symposium on Theory of computing: 326–333.
- 1 2 3 Irony, Dror; Toledo, Sivan; Tiskin, Alexander (September 2004). "Communication lower bounds for distributed-memory matrix multiplication". J. Parallel Distrib. Comput. 64 (9): 1017–1026. doi:10.1016/j.jpdc.2004.03.021.
- 1 2 Agarwal, R.C.; Balle, S. M.; Gustavson, F. G.; Joshi, M.; Palkar, P. (September 1995). "A three-dimensional approach to parallel matrix multiplication". IBM J. Res. Dev. 39 (5): 575–582. doi:10.1147/rd.395.0575.
- ↑ Solomonik, Edgar; Demmel, James (2011). "Communication-optimal parallel 2.5D matrix multiplication and LU factorization algorithms". Proceedings of the 17th international conference on Parallel processing. Part II: 90–109. doi:10.1007/978-3-642-23397-5_10.
- ↑ Pietracaprina, A.; Pucci, G.; Riondato, M.; Silvestri, F.; Upfal, E. (2012). "Space-Round Tradeoffs for MapReduce Computations". Proc. of 26th ACM International Conference on Supercomputing. Venice (Italy): ACM. pp. 235–244. doi:10.1145/2304576.2304607.
References
- Henry Cohn, Robert Kleinberg, Balázs Szegedy, and Chris Umans. Group-theoretic Algorithms for Matrix Multiplication. arXiv:math.GR/0511460. Proceedings of the 46th Annual Symposium on Foundations of Computer Science, 23–25 October 2005, Pittsburgh, PA, IEEE Computer Society, pp. 379–388.
- Henry Cohn, Chris Umans. A Group-theoretic Approach to Fast Matrix Multiplication. arXiv:math.GR/0307321. Proceedings of the 44th Annual IEEE Symposium on Foundations of Computer Science, 11–14 October 2003, Cambridge, MA, IEEE Computer Society, pp. 438–449.
- Coppersmith, D.; Winograd, S. (1990). "Matrix multiplication via arithmetic progressions". J. Symbolic Comput. 9: 251–280. doi:10.1016/s0747-7171(08)80013-2.
- Horn, Roger A.; Johnson, Charles R. (1991), Topics in Matrix Analysis, Cambridge University Press, ISBN 978-0-521-46713-1
- Knuth, D.E., The Art of Computer Programming Volume 2: Seminumerical Algorithms. Addison-Wesley Professional; 3 edition (November 14, 1997). ISBN 978-0-201-89684-8. pp. 501.
- Press, William H.; Flannery, Brian P.; Teukolsky, Saul A.; Vetterling, William T. (2007), Numerical Recipes: The Art of Scientific Computing (3rd ed.), Cambridge University Press, ISBN 978-0-521-88068-8.
- Ran Raz. On the complexity of matrix product. In Proceedings of the thirty-fourth annual ACM symposium on Theory of computing. ACM Press, 2002. doi:10.1145/509907.509932.
- Robinson, Sara, Toward an Optimal Algorithm for Matrix Multiplication, SIAM News 38(9), November 2005. PDF
- Strassen, Volker, Gaussian Elimination is not Optimal, Numer. Math. 13, p. 354-356, 1969.
- Styan, George P. H. (1973), "Hadamard Products and Multivariate Statistical Analysis", Linear Algebra and its Applications, 6: 217–240, doi:10.1016/0024-3795(73)90023-2
- Vassilevska Williams, Virginia, Multiplying matrices faster than Coppersmith-Winograd, Manuscript, May 2012. PDF
External links
| The Wikibook The Book of Mathematical Proofs has a page on the topic of: Proofs of properties of matrices |
| The Wikibook Linear Algebra has a page on the topic of: Matrix multiplication |
| The Wikibook Applicable Mathematics has a page on the topic of: Multiplying Matrices |
- How to Multiply Matrices
- Matrix Multiplication Calculator Online
- The Simultaneous Triple Product Property and Group-theoretic Results for the Exponent of Matrix Multiplication
- WIMS Online Matrix Multiplier
- Wijesuriya, Viraj B., Daniweb: Sample Code for Matrix Multiplication using MPI Parallel Programming Approach, retrieved 2010-12-29
- Linear algebra: matrix operations Multiply or add matrices of a type and with coefficients you choose and see how the result was computed.
- Matrix Multiplication in Java – Dr. P. Viry
- "Matrix multiplication as composition". Essence of linear algebra. August 8, 2016 – via YouTube.