Typestate analysis
Typestate analysis, sometimes called protocol analysis, is a form of program analysis employed in programming languages. It is most commonly applied to object-oriented languages. Typestates define valid sequences of operations that can be performed upon an instance of a given type. Typestates, as the name suggests, associate state information with variables of that type. This state information is used to determine at compile-time which operations are valid to be invoked upon an instance of the type. Operations performed on an object that would usually only be executed at run-time are performed upon the type state information which is modified to be compatible with the new state of the object.
Typestates are capable of representing behavioral type refinements such as "method A must be invoked before method B is invoked, and method C may not be invoked in between". Typestates are well-suited to representing resources that use open/close semantics by enforcing semantically valid sequences such as "open then close" as opposed to invalid sequences such as leaving a file in an open state. Such resources include filesystem elements, transactions, connections and protocols. For instance, developers may want to specify that files or sockets must be opened before they are read or written, and that they can no longer be read or written if they have been closed. The name "typestate" stems from the fact that this kind of analysis often models each type of object as a finite state machine. In this state machine, each state has a well-defined set of permitted methods/messages, and method invocations may cause state transitions. Petri nets have also been proposed as a possible behavioral model for use with refinement types.[1]
The word "typestate" was coined by Strom and Yemini in a 1986 article that described how to use typestate to track the degree of initialisation of variables, guaranteeing that operations would never be applied on improperly initialised data.[2] In recent years, various studies have developed ways of applying the typestate concept to object-oriented languages.[3][4]
Approach
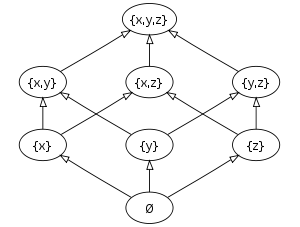
struct{int x;int y;int z;}. The least element ⊥ coincides with the state ∅ of no struct components initialized.
Strom and Yemini (1986) required the set of typestates for a given type to be partially ordered such that a lower typestate can be obtained from a higher one by discarding some information. For example, an int variable in C typically has the typestates "uninitialized" < "initialized", and a FILE* pointer may have the typestates "unallocated" < "allocated, but uninitialized" < "initialized, but file not opened" < "file opened". Moreover, Strom and Yemini require that each two typestates have a greatest lower bound, i.e. that the partial order is even a meet-semilattice; and that each order has a least element, always called "⊥".
Their analysis is based on the simplification that each variable v is assigned only one typestate for each point in the program text; if a point p is reached by two different execution paths and v inherits different typestates via each path, then the typestate of v at p is taken to be the greatest lower bound of the inherited typestates. For example, in the following C snippet, the variable n inherits the typestate "initialized" and "uninitialized" from the then and the (empty) else part, respectively, hence it has typestate "uninitialized" after the whole conditional statement.
int n; // here, n has typestate "uninitialized"
if (...) {
n = 5; // here, n has typestate "initialized"
} else {
/*do nothing*/ // here, n has typestate "uninitialized"
} // here, n has typestate "uninitialized" = greatest_lower_bound("initialized","uninitialized")
Every basic operation[note 1] has to be equipped with a typestate transition, i.e. for each parameter the required and ensured typestate before and after the operation, respectively. For example, an operation fwrite(...,fd) requires fd to have typestate "file opened". More precisely, an operation may have several outcomes, each of which needs its own typestate transition. For example, the C code FILE *fd=fopen("foo","r") sets fd's typestate to "file opened" and "unallocated" if opening succeeds and fails, respectively.
For each two typestates t1 <· t2, a unique typestate coercion operation needs to be provided which, when applied to an object of typestate t2, reduces its typestate to t1, possibly by releasing some resources. For example, fclose(fd) coerces fd's typestate from "file opened" to "initialized, but file not opened".
A program execution is called typestate-correct if
- before each basic operation, all parameters have exactly the typestate required by the operations's typestate transition, and
- on program termination, all variables are in typestate ⊥.[note 2]
A program text is called typestate-consistent if it can be transformed, by adding appropriate typestate coercions, to a program whose points can be statically labelled with typestates such that any path allowed by the control flow is typestate-correct. Strom and Yemini give a linear-time algorithm that checks a given program text for typestate-consistency, and computes where to insert which coercion operation, if any.
Challenges
In order to achieve a precise and effective typestate analysis, it is necessary to address the problem of aliasing. Aliasing occurs when an object has more than one reference or pointer that points to it. For the analysis to be correct, state changes to a given object must be reflected in all references that point to that object, but in general it is a difficult problem to track all such references. This becomes especially hard if the analysis needs to be modular, that is, applicable to each part of a large program separately without taking the rest of the program into account.
As another issue, for some programs, the method of taking the greatest lower bound at converging execution paths and adding corresponding down-coercion operations appears to be inadequate.
For example, before the return 1 in the following program,[note 3] all components x, y, and z of coord are initialized, but Strom's and Yemini's approach fails to recognize this, since each initialization of a struct component in the loop body has to be down-coerced at loop re-entry to meet the typestate of the very first loop entry, viz. ⊥. A related problem is that this example would require overloading of typestate transitions; for example, parse_int_attr("x",&coord->x) changes a typestate "no component initialized" to "x component initialized", but also "y component initialized" to "x and y component initialized".
int parse_coord(struct{int x;int y;int z;} *coord) {
int seen = 0; /* remember which attributes have been parsed */
while (1)
if (parse_int_attr("x",&coord->x)) seen |= 1;
else if (parse_int_attr("y",&coord->y)) seen |= 2;
else if (parse_int_attr("z",&coord->z)) seen |= 4;
else break;
if (seen != 7) /* some attribute missing, fail */
return 0;
... /* all attributes present, do some computations and succeed */
return 1;
}
Typestate Inference
There are several approaches seeking to infer typestates out of programs (or even other artifacts such as contracts). Many of them can infer typestates at compile time [5][6][7][8] and others mine the models dynamically.[9][10][11][12][13][14]
Languages supporting typestate
Typestate is an experimental concept that has not yet crossed over into mainstream programming languages. However, many academic projects actively investigate how to make it more useful as an everyday programming technique. One example is the Plaid language, which is being developed by Jonathan Aldrich's group at Carnegie Mellon University.[15] Other examples are the Clara[16] language research framework and earlier versions of the Rust language.
See also
Notes
- ↑ these include language constructs, e.g.
+=in C, and standard library routines, e.g.fopen() - ↑ This aims at ensuring that e.g. all files have been closed, and all
malloced memory has beenfreed. In most programming languages, a variable's lifetime may end before program termination; the notion of typestate-correctness has then to be sharpened accordingly. - ↑ assuming that
int parse_int_attr(const char *name,int *val)initializes*valwhenever it succeeds
References
- ↑ Jorge Luis Guevara D´ıaz (2010). "Typestate oriented design - A coloured petri net approach" (PDF).
- ↑ Strom, Robert E.; Yemini, Shaula (1986). "Typestate: A programming language concept for enhancing software reliability" (PDF). IEEE Transactions on Software Engineering. IEEE. 12: 157–171. doi:10.1109/tse.1986.6312929.
- ↑ DeLine, Robert; Fähndrich, Manuel (2004). "Typestates for Objects". ECOOP 2004: Proceedings of the 18th European Conference on Object-Oriented Programming. Lecture Notes in Computer Science. Springer. 3086: 465–490. doi:10.1007/978-3-540-24851-4_21. ISBN 978-3-540-22159-3.
- ↑ Bierhoff, Kevin; Aldrich, Jonathan (2007). "Modular Typestate Checking of Aliased Objects". OOPSLA '07: Proceedings of the 22nd ACM SIGPLAN Conference on Object-Oriented Programming: Systems, Languages and Applications: 301–320. doi:10.1145/1297027.1297050. ISBN 9781595937865.
- ↑ Guido de Caso, Victor Braberman, Diego Garbervetsky, and Sebastian Uchitel. 2013. Enabledness-based program abstractions for behavior validation. ACM Trans. Softw. Eng. Methodol. 22, 3, Article 25 (July 2013), 46 pages.
- ↑ R. Alur, P. Cerny, P. Madhusudan, and W. Nam. Synthesis of interface specifications for Java classes, 32nd ACM Symposium on Principles of Programming Languages, 2005
- ↑ Giannakopoulou, D., and Pasareanu, C.S., "Interface Generation and Compositional Verification in JavaPathfinder", FASE 2009.
- ↑ Thomas A. Henzinger, Ranjit Jhala, and Rupak Majumdar. Permissive interfaces. Proceedings of the 13th Annual Symposium on Foundations of Software Engineering (FSE), ACM Press, 2005, pp. 31-40.
- ↑ Valentin Dallmeier, Christian Lindig, Andrzej Wasylkowski, and Andreas Zeller. 2006. Mining object behavior with ADABU. In Proceedings of the 2006 international workshop on Dynamic systems analysis (WODA '06). ACM, New York, NY, USA, 17-24
- ↑ Carlo Ghezzi, Andrea Mocci, and Mattia Monga. 2009. Synthesizing intensional behavior models by graph transformation. In Proceedings of the 31st International Conference on Software Engineering (ICSE '09). IEEE Computer Society, Washington, DC, USA, 430-440
- ↑ Mark Gabel and Zhendong Su. 2008. Symbolic mining of temporal specifications. In Proceedings of the 30th international conference on Software engineering (ICSE '08). ACM, New York, NY, USA, 51-60.
- ↑ Davide Lorenzoli, Leonardo Mariani, and Mauro Pezzè. 2008. Automatic generation of software behavioral models. In Proceedings of the 30th international conference on Software engineering (ICSE '08). ACM, New York, NY, USA, 501-510
- ↑ Ivan Beschastnikh, Yuriy Brun, Sigurd Schneider, Michael Sloan, and Michael D. Ernst. 2011. Leveraging existing instrumentation to automatically infer invariant-constrained models. In Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering (ESEC/FSE '11). ACM, New York, NY, USA, 267-277
- ↑ Pradel, M.; Gross, T.R., "Automatic Generation of Object Usage Specifications from Large Method Traces," Automated Software Engineering, 2009. ASE '09. 24th IEEE/ACM International Conference on , vol., no., pp.371,382, 16-20 Nov. 2009
- ↑ Aldrich, Jonathan. "The Plaid Programming Language". Retrieved 22 July 2012.
- ↑ Bodden, Eric. "Clara". Retrieved 23 July 2012.