Norm (mathematics)
In linear algebra, functional analysis, and related areas of mathematics, a norm is a function that assigns a strictly positive length or size to each vector in a vector space—save for the zero vector, which is assigned a length of zero. A seminorm, on the other hand, is allowed to assign zero length to some non-zero vectors (in addition to the zero vector).
A norm must also satisfy certain properties pertaining to scalability and additivity which are given in the formal definition below.
A simple example is the 2-dimensional Euclidean space R2 equipped with the Euclidean norm. Elements in this vector space (e.g., (3, 7)) are usually drawn as arrows in a 2-dimensional cartesian coordinate system starting at the origin (0, 0). The Euclidean norm assigns to each vector the length of its arrow. Because of this, the Euclidean norm is often known as the magnitude.
A vector space on which a norm is defined is called a normed vector space. Similarly, a vector space with a seminorm is called a seminormed vector space. It is often possible to supply a norm for a given vector space in more than one way.
Definition
Given a vector space V over a subfield F of the complex numbers, a norm on V is a function p: V → R with the following properties:[1]
For all a ∈ F and all u, v ∈ V,
- p(av) = | a | p(v), (absolute homogeneity or absolute scalability).
- p(u + v) ≤ p(u) + p(v) (triangle inequality or subadditivity).
- If p(v) = 0 then v is the zero vector (separates points).
By the first axiom, absolute homogeneity, we have p(0) = 0 and p(−v) = p(v), so that by the triangle inequality
- p(v) ≥ 0 (non-negativity).
A seminorm on V is a function p : V → R with the properties 1. and 2. above.
Every vector space V with seminorm p induces a normed space V/W, called the quotient space, where W is the subspace of V consisting of all vectors v in V with p(v) = 0. The induced norm on V/W is clearly well-defined and is given by:
- p(W + v) = p(v).
Two norms (or seminorms) p and q on a vector space V are equivalent if there exist two real constants c and C, with c > 0 such that
- for every vector v in V, one has that: c q(v) ≤ p(v) ≤ C q(v).
A topological vector space is called normable (seminormable) if the topology of the space can be induced by a norm (seminorm).
Notation
If a norm p : V → R is given on a vector space V then the norm of a vector v ∈ V is usually denoted by enclosing it within double vertical lines: ‖v‖ = p(v). Such notation is also sometimes used if p is only a seminorm.
For the length of a vector in Euclidean space (which is an example of a norm, as explained below), the notation | v | with single vertical lines is also widespread.
In Unicode, the codepoint of the "double vertical line" character ‖ is U+2016. The double vertical line should not be confused with the "parallel to" symbol, Unicode U+2225 ( ∥ ). This is usually not a problem because the former is used in parenthesis-like fashion, whereas the latter is used as an infix operator. The double vertical line used here should also not be confused with the symbol used to denote lateral clicks, Unicode U+01C1 ( ǁ ). The single vertical line | is called "vertical line" in Unicode and its codepoint is U+007C.
Examples
- All norms are seminorms.
- The trivial seminorm has p(x) = 0 for all x in V.
- Every linear form f on a vector space defines a seminorm by x → | f(x) |.
Absolute-value norm
The absolute value

is a norm on the one-dimensional vector spaces formed by the real or complex numbers.
The absolute value norm is a special case of the L1 norm.
Euclidean norm
On an n-dimensional Euclidean space Rn, the intuitive notion of length of the vector x = (x1, x2, ..., xn) is captured by the formula

This gives the ordinary distance from the origin to the point x, a consequence of the Pythagorean theorem. The Euclidean norm is by far the most commonly used norm on Rn, but there are other norms on this vector space as will be shown below. However all these norms are equivalent in the sense that they all define the same topology.
On an n-dimensional complex space Cn the most common norm is

In both cases we can also express the norm as the square root of the inner product of the vector and itself:

where x is represented as a column vector ([x1; x2; ...; xn]), and x∗ denotes its conjugate transpose.
This formula is valid for any inner product space, including Euclidean and complex spaces. For Euclidean spaces, the inner product is equivalent to the dot product. Hence, in this specific case the formula can be also written with the following notation:

The Euclidean norm is also called the Euclidean length, L2 distance, ℓ2 distance, L2 norm, or ℓ2 norm; see Lp space.
The set of vectors in Rn+1 whose Euclidean norm is a given positive constant forms an n-sphere.
Euclidean norm of a complex number
The Euclidean norm of a complex number is the absolute value (also called the modulus) of it, if the complex plane is identified with the Euclidean plane R2. This identification of the complex number x + i y as a vector in the Euclidean plane, makes the quantity (as first suggested by Euler) the Euclidean norm associated with the complex number.

Taxicab norm or Manhattan norm

The name relates to the distance a taxi has to drive in a rectangular street grid to get from the origin to the point x.
The set of vectors whose 1-norm is a given constant forms the surface of a cross polytope of dimension equivalent to that of the norm minus 1. The Taxicab norm is also called the 1 norm. The distance derived from this norm is called the Manhattan distance or 1 distance.

The 1-norm is simply the sum of the absolute values of the columns.
In contrast,

is not a norm because it may yield negative results.
p-norm
Let p ≥ 1 be a real number.

For p = 1 we get the taxicab norm, for p = 2 we get the Euclidean norm, and as p approaches the p-norm approaches the infinity norm or maximum norm. The p-norm is related to the generalized mean or power mean.

This definition is still of some interest for 0 < p < 1, but the resulting function does not define a norm,[2] because it violates the triangle inequality. What is true for this case of 0 < p < 1, even in the measurable analog, is that the corresponding Lp class is a vector space, and it is also true that the function

(without pth root) defines a distance that makes Lp(X) into a complete metric topological vector space. These spaces are of great interest in functional analysis, probability theory, and harmonic analysis. However, outside trivial cases, this topological vector space is not locally convex and has no continuous nonzero linear forms. Thus the topological dual space contains only the zero functional.
The partial derivative of the p-norm is given by

The derivative with respect to x, therefore, is

where denotes Hadamard product and is used for absolute value of each component of the vector.


For the special case of p = 2, this becomes

or

Maximum norm (special case of: infinity norm, uniform norm, or supremum norm)
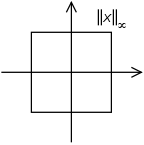
If is some vector such that , then:



The set of vectors whose infinity norm is a given constant, c, forms the surface of a hypercube with edge length 2c.
Zero norm
In probability and functional analysis, the zero norm induces a complete metric topology for the space of measurable functions and for the F-space of sequences with F–norm , which is discussed by Stefan Rolewicz in Metric Linear Spaces.[3] Here we mean by F-norm some real-valued function on an F-space with distance d, such that . One should note that the F-norm described above is not a norm in the usual sense because it lacks the required homogeneity property.



Hamming distance of a vector from zero
In metric geometry, the discrete metric takes the value one for distinct points and zero otherwise. When applied coordinate-wise to the elements of a vector space, the discrete distance defines the Hamming distance, which is important in coding and information theory. In the field of real or complex numbers, the distance of the discrete metric from zero is not homogeneous in the non-zero point; indeed, the distance from zero remains one as its non-zero argument approaches zero. However, the discrete distance of a number from zero does satisfy the other properties of a norm, namely the triangle inequality and positive definiteness. When applied component-wise to vectors, the discrete distance from zero behaves like a non-homogeneous "norm", which counts the number of non-zero components in its vector argument; again, this non-homogeneous "norm" is discontinuous.
In signal processing and statistics, David Donoho referred to the zero "norm" with quotation marks. Following Donoho's notation, the zero "norm" of x is simply the number of non-zero coordinates of x, or the Hamming distance of the vector from zero. When this "norm" is localized to a bounded set, it is the limit of p-norms as p approaches 0. Of course, the zero "norm" is not truly a norm, because it is not positive homogeneous. Indeed, it is not even an F-norm in the sense described above, since it is discontinuous, jointly and severally, with respect to the scalar argument in scalar–vector multiplication and with respect to its vector argument. Abusing terminology, some engineers omit Donoho's quotation marks and inappropriately call the number-of-nonzeros function the L0 norm, echoing the notation for the Lebesgue space of measurable functions.
Other norms
Other norms on Rn can be constructed by combining the above; for example

is a norm on R4.
For any norm and any injective linear transformation A we can define a new norm of x, equal to

In 2D, with A a rotation by 45° and a suitable scaling, this changes the taxicab norm into the maximum norm. In 2D, each A applied to the taxicab norm, up to inversion and interchanging of axes, gives a different unit ball: a parallelogram of a particular shape, size and orientation. In 3D this is similar but different for the 1-norm (octahedrons) and the maximum norm (prisms with parallelogram base).
All the above formulas also yield norms on Cn without modification.
Infinite-dimensional case
The generalization of the above norms to an infinite number of components leads to the Lp spaces, with norms

(for complex-valued sequences x resp. functions f defined on ), which can be further generalized (see Haar measure).

Any inner product induces in a natural way the norm

Other examples of infinite dimensional normed vector spaces can be found in the Banach space article.
Properties
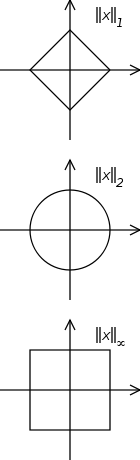
The concept of unit circle (the set of all vectors of norm 1) is different in different norms: for the 1-norm the unit circle in R2 is a square, for the 2-norm (Euclidean norm) it is the well-known unit circle, while for the infinity norm it is a different square. For any p-norm it is a superellipse (with congruent axes). See the accompanying illustration. Due to the definition of the norm, the unit circle must be convex and centrally symmetric (therefore, for example, the unit ball may be a rectangle but cannot be a triangle, and for a p-norm).

In terms of the vector space, the seminorm defines a topology on the space, and this is a Hausdorff topology precisely when the seminorm can distinguish between distinct vectors, which is again equivalent to the seminorm being a norm. The topology thus defined (by either a norm or a seminorm) can be understood either in terms of sequences or open sets. A sequence of vectors is said to converge in norm to if as . Equivalently, the topology consists of all sets that can be represented as a union of open balls.




Two norms ‖•‖α and ‖•‖β on a vector space V are called equivalent if there exist positive real numbers C and D such that for all x in V

For instance, on , if p > r > 0, then


In particular,



i.e.,
- .

If the vector space is a finite-dimensional real or complex one, all norms are equivalent. On the other hand, in the case of infinite-dimensional vector spaces, not all norms are equivalent.
Equivalent norms define the same notions of continuity and convergence and for many purposes do not need to be distinguished. To be more precise the uniform structure defined by equivalent norms on the vector space is uniformly isomorphic.
Every (semi)-norm is a sublinear function, which implies that every norm is a convex function. As a result, finding a global optimum of a norm-based objective function is often tractable.
Given a finite family of seminorms pi on a vector space the sum

is again a seminorm.
For any norm p on a vector space V, we have that for all u and v ∈ V:
- p(u ± v) ≥ |p(u) − p(v)|.
Proof: Applying the triangular inequality to both and :






Thus, p(u ± v) ≥ |p(u) − p(v)|.
If and are normed spaces and is a continuous linear map, then the norm of and the norm of the transpose of are equal.[4]




For the lp norms, we have Hölder's inequality[5]

A special case of this is the Cauchy–Schwarz inequality:[5]

Classification of seminorms: absolutely convex absorbing sets
All seminorms on a vector space V can be classified in terms of absolutely convex absorbing sets in V. To each such set, A, corresponds a seminorm pA called the gauge of A, defined as
- pA(x) := inf{α : α > 0, x ∈ αA}
with the property that
- {x : pA(x) < 1} ⊆ A ⊆ {x : pA(x) ≤ 1}.
Conversely:
Any locally convex topological vector space has a local basis consisting of absolutely convex sets. A common method to construct such a basis is to use a family (p) of seminorms p that separates points: the collection of all finite intersections of sets {p < 1/n} turns the space into a locally convex topological vector space so that every p is continuous.
Such a method is used to design weak and weak* topologies.
norm case:
- Suppose now that (p) contains a single p: since (p) is separating, p is a norm, and A = {p < 1} is its open unit ball. Then A is an absolutely convex bounded neighbourhood of 0, and p = pA is continuous.
- The converse is due to Kolmogorov: any locally convex and locally bounded topological vector space is normable. Precisely:
- If V is an absolutely convex bounded neighbourhood of 0, the gauge gV (so that V = {gV < 1}) is a norm.
Generalizations
There are several generalizations of norms and semi-norms. If p is absolute homogeneity but in place of subadditivity we require that
| 2′. | there is a such that for all |



then p satisfies the triangle inequality but is called a quasi-seminorm and the smallest value of b for which this holds is called the multiplier of p; if in addition p separates points then it is called a quasi-norm.
On the other hand, if p satisfies the triangle inequality but in place of absolute homogeneity we require that
| 1′. | there exists a k such that and for all and scalars : |




then p is called a k-seminorm.
We have the following relationship between quasi-seminorms and k-seminorms:
- Suppose that q is a quasi-seminorm on a vector space X with multiplier b. If then there exists k-seminorm p on X equivalent to q.

The concept of norm in composition algebras does not share the usual properties of a norm. A composition algebra (A, *, N) consists of an algebra over a field A, an involution *, and a quadratic form N, which is called the "norm". In several cases N is an isotropic quadratic form so that A has at least one null vector, contrary to the separation of points required for the usual norm discussed in this article.
See also
- Normed vector space
- Asymmetric norm
- Matrix norm
- Gowers norm
- Mahalanobis distance
- Manhattan distance
- Relation of norms and metrics
Notes
- ↑ Prugovečki 1981, page 20
- ↑ Except in R1, where it coincides with the Euclidean norm, and R0, where it is trivial.
- ↑ Rolewicz, Stefan (1987), Functional analysis and control theory: Linear systems, Mathematics and its Applications (East European Series), 29 (Translated from the Polish by Ewa Bednarczuk ed.), Dordrecht; Warsaw: D. Reidel Publishing Co.; PWN—Polish Scientific Publishers, pp. xvi,524, ISBN 90-277-2186-6, MR 920371, OCLC 13064804
- ↑ Treves pp. 242–243
- 1 2 Golub, Gene; Van Loan, Charles F. (1996). Matrix Computations (Third ed.). Baltimore: The Johns Hopkins University Press. p. 53. ISBN 0-8018-5413-X.
References
- Bourbaki, Nicolas (1987). "Chapters 1–5". Topological vector spaces. Springer. ISBN 3-540-13627-4.
- Prugovečki, Eduard (1981). Quantum mechanics in Hilbert space (2nd ed.). Academic Press. p. 20. ISBN 0-12-566060-X.
- Trèves, François (1995). Topological Vector Spaces, Distributions and Kernels. Academic Press, Inc. pp. 136–149, 195–201, 240–252, 335–390, 420–433. ISBN 0-486-45352-9.
- Khaleelulla, S. M. (1982). Counterexamples in Topological Vector Spaces. Lecture Notes in Mathematics. 936. Springer-Verlag. pp. 3–5. ISBN 978-3-540-11565-6. Zbl 0482.46002.