reCAPTCHA
 | |
| Original author(s) |
|
|---|---|
| Developer(s) | Google Inc. |
| Initial release | May 27, 2007 |
| Development status | Active |
| Type |
Classic version: CAPTCHA New version: checkbox |
| Website |
www |
reCAPTCHA is a CAPTCHA-like system designed to establish that a computer user is human (normally in order to protect websites from bots) and, at the same time, assist in the digitization of books. The reCAPTCHA service supplies subscribing websites with images of words that are hard to read for optical character recognition (OCR) software. The subscribing websites (whose purposes are generally unrelated to the book digitization project) present these images for humans to decipher as CAPTCHA words, as part of their normal validation procedures. They then return the results to the reCAPTCHA service, which sends the results to the digitization projects.
reCAPTCHA was originally developed by Luis von Ahn, Ben Maurer, Colin McMillen, David Abraham and Manuel Blum at Carnegie Mellon University's main Pittsburgh campus. It was acquired by Google in September 2009.[1]
reCAPTCHA has completed digitizing the archives of The New York Times and books from Google Books.[2] The archive can be searched from the New York Times Article Archive, where more than 13 million articles in total have been archived, dating from 1851 to the present day.
The system has been reported as displaying over 100 million CAPTCHAs every day,[2] on sites such as Facebook, TicketMaster, Twitter, 4chan, CNN.com, StumbleUpon,[3] Craigslist (since June 2008),[4] and the U.S. National Telecommunications and Information Administration's digital TV converter box coupon program website (as part of the US DTV transition).[5]
reCAPTCHA's slogan was "Stop Spam, Read Books.",[6] until the introduction of a new version of the reCAPTCHA plugin in 2014; the slogan has now disappeared from the website[7] and from the classic version of the reCAPTCHA plugin. A new system featuring image verification was also introduced. In this system, users are asked to just click on a checkbox (the system will verify whether the user is a human or not, for example, with some clues such as already-known cookies or mouse movements within the ReCAPTCHA frame) or, if it fails, select one or more images from a selection of nine images.[8]
Through mass-collaboration, reCAPTCHA is helping to digitize books that are too illegible to be scanned by computers, as well as translate books to different languages.[9]
Origin
Distributed Proofreaders was the first project to volunteer its time to decipher scanned text that could not be read by OCR. It works with Project Gutenberg to digitize public domain material and uses methods quite different from reCAPTCHA.
The reCAPTCHA program originated with Guatemalan computer scientist Luis von Ahn,[10] and was aided by a MacArthur Fellowship. An early CAPTCHA developer, he realized "he had unwittingly created a system that was frittering away, in ten-second increments, millions of hours of a most precious resource: human brain cycles".[11][12]
Operation
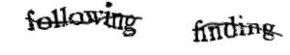
Scanned text is subjected to analysis by two different optical character recognition programs - one of them, as mentioned the project developer Ben Maurer, is ABBYY FineReader.[14] Their respective outputs are then aligned with each other by standard string-matching algorithms and compared both to each other and to an English dictionary. Any word that is deciphered differently by both OCR programs or that is not in the English dictionary is marked as "suspicious" and converted into a CAPTCHA. The suspicious word is displayed, out of context, sometimes along with a control word already known. If the human types the control word correctly, then the response to the questionable word is accepted as probably valid. If enough users were to correctly type the control word, but incorrectly type the second word which OCR had failed to recognize, then the digital version of documents could end up containing the incorrect word. The identification performed by each OCR program is given a value of 0.5 points, and each interpretation by a human is given a full point. Once a given identification hits 2.5 points, the word is considered valid. Those words that are consistently given a single identity by human judges are later recycled as control words.[15] If the first three guesses match each other but do not match either of the OCRs, they are considered a correct answer, and the word becomes a control word.[16] When six users reject a word before any correct spelling is chosen, the word is discarded as unreadable.[16]
The original reCAPTCHA method was designed to show the questionable words separately, as out-of-context correction, rather than in use, such as within a phrase of five words from the original document.[17] Also, the control word might mislead context for the second word, such as a request of "/metal/ /fife/" being entered as "metal file" due to the logical connection of filing with a metal tool being considered more common than the musical instrument "fife".
In 2012, reCAPTCHA began using photographs of house numbers taken from Google's Street View project, in addition to scanned words.[18]

In 2014, reCAPTCHA implemented another system in which users are asked to select one or more images from a selection of nine images.[8]
No CAPTCHA reCAPTCHA

In 2013, reCAPTCHA began implementing behavioral analysis of the browser's interactions with the CAPTCHA to predict whether the user was a human or a bot before displaying the captcha, and presenting a "considerably more difficult" captcha in cases where it had reason to think the user might be a bot. By end of 2014 this mechanism started to be rolled out to most of the public Google services.[19]
Implementation
The reCAPTCHA tests are displayed from the central site of the reCAPTCHA project, which supplies the words to be deciphered. This is done through a JavaScript API with the server making a callback to reCAPTCHA after the request has been submitted. The reCAPTCHA project provides libraries for various programming languages and applications to make this process easier. reCAPTCHA is a free service (that is, the CAPTCHA images are provided to websites free of charge, in return for assistance with the decipherment),[20] but the reCAPTCHA software itself is not open source.[21]
Also, reCAPTCHA offers plugins for several web-application platforms, like ASP.NET, Ruby, or PHP, to ease the implementation of the service.[22]
Criticism
Some have criticized Google for using reCAPTCHA as a source of unpaid labor.[23] They say Google is unfairly using people around the world to help it transcribe books, addresses, and newspapers without any compensation.
The use of reCAPTCHA has been labelled "a serious barrier to internet use" for people with sight problems or disabilities such as dyslexia by a BBC journalist.[24]
Andrew Munsell, in his article "Captchas Are Becoming Ridiculous" states "A couple of years ago, I don’t remember being truly baffled by a captcha. In fact, reCAPTCHA was one of the better systems I’d seen. It wasn’t difficult to solve, and it seemed to work when I used it on my own websites." [25] Munsell goes on to state, after encountering a series of unintelligible images that despite refreshing "Again, and again, and again. The captchas were not only difficult for a computer to read, but impossible for a human." Munsell then provided numerous examples.
Security

The main purpose of a CAPTCHA system is to prevent automated access to a system by computer programs or "bots". On 14 December 2009, Jonathan Wilkins released a paper describing weaknesses in reCAPTCHA that allowed a solve rate of 18%.[27][28][29]
On 1 August 2010, Chad Houck gave a presentation to the DEF CON 18 Hacking Conference detailing a method to reverse the distortion added to images which allowed a computer program to determine a valid response 10% of the time.[30][31] The reCAPTCHA system was modified on 21 July 2010, before Houck was to speak on his method. Houck modified his method to what he described as an "easier" CAPTCHA to determine a valid response 31.8% of the time. Houck also mentioned security defenses in the system, including a high security lock out if an invalid response is given 32 times in a row.[32]
On 26 May 2012, Adam, C-P and Jeffball of DC949 gave a presentation at the LayerOne hacker conference detailing how they were able to achieve an automated solution with an accuracy rate of 99.1%.[33] Their tactic was to use techniques from machine learning, a subfield of artificial intelligence, to analyse the audio version of reCAPTCHA which is available for the visually impaired. Google released a new version of reCAPTCHA just hours before their talk, making major changes to both the audio and visual versions of their service. In this release, the audio version was increased in length from 8 seconds to 30 seconds, and is much more difficult to understand, both for humans as well as bots. In response to this update and the following one, the members of DC949 released two more versions of Stiltwalker which beat reCAPTCHA with an accuracy of 60.95% and 59.4% respectively. After each successive break, Google updated reCAPTCHA within a few days. According to DC949, they often reverted to features that had been previously hacked.
On 27 June 2012, Claudia Cruz, Fernando Uceda, and Leobardo Reyes (a group of students from Mexico) published a paper showing a system running on reCAPTCHA images with an accuracy of 82%.[34] The authors have not said if their system can solve recent reCAPTCHA images, although they claim their work to be intelligent OCR and robust to some, if not all changes in the image database.
In an August 2012 presentation given at BsidesLV 2012, DC949 called the latest version "unfathomably impossible for humans" - they were not able to solve them manually either.[33] The web accessibility organization WebAIM reported in May 2012, "Over 90% of respondents [screen reader users] find CAPTCHA to be very or somewhat difficult."[35]
reCAPTCHA frequently modifies its system, requiring spammers to frequently update their methods of decoding, which may frustrate potential abusers.
Only words that both OCR programs failed to recognize are used as control words. Thus, any program that can recognize these words with nonnegligible probability would represent an improvement over state of the art OCR programs.[16]
Derivative projects
reCAPTCHA had also created project Mailhide, which protects email addresses on web pages from being harvested by spammers.[36] By default, the email address is converted into a format that does not allow a crawler to see the full email address; for example, "mailme@example.com" would be converted to "mai...@example.com". The visitor would then click on the "..." and solve the CAPTCHA in order to obtain the full email address. One can also edit the pop-up code so that none of the address is visible.
References
- ↑ "Teaching computers to read: Google acquires reCAPTCHA". Google. Retrieved 2009-09-16.
- 1 2 "reCAPTCHA FAQ". Google. Retrieved 2011-06-12.
- ↑ Rubens, Paul (2007-10-02). "Spam weapon helps preserve books". BBC.
- ↑ "Fight Spam, Digitize Books". Craigslist Blog. June 2008.
- ↑ TV Converter Box Program
- ↑ "reCAPTCHA: Stop Spam, Read Books". Google. Retrieved 2013-07-10.
- ↑ "recaptcha". Google. Retrieved 2015-01-03.
- 1 2 Greenberg, Andy (December 3, 2014). "Google Can Now Tell You're Not a Robot with Just One Click". Wired. Retrieved October 1, 2015.
- ↑ "Massive-scale online collaboration". www.ted.com. Retrieved 2015-10-24.
- ↑ ""Full Interview: Luis von Ahn on Duolingo", Spark, November 2011". Canadian Broadcasting Corporation. 2011-11-30. Retrieved 2013-07-10.
- ↑ Hutchinson, Alex (March 2009). "Human Resources: The job you didn't even know you had". The Walrus. pp. 15–16.
- ↑ Hutchinson, Alex. "Human Resources: The job you didn't even know you had". The Walrus. Retrieved 7 December 2015.
- ↑ http://techcrunch.com/2007/09/16/recaptcha-using-captchas-to-digitize-books/
- ↑ "What is the best OCR software on the market?". Retrieved 2016-03-21.
- ↑ Timmer, John (2008-08-14). "CAPTCHAs work? for digitizing old, damaged texts, manuscripts". Ars Technica. Retrieved 2008-12-09.
- 1 2 3 Luis; Maurer, Ben; McMillen, Colin; Abraham, David; Blum, Manuel (2008). "reCAPTCHA: Human-Based Character Recognition via Web Security Measures" (PDF)". Science. 321 (5895): 1465–1468. doi:10.1126/science.1160379. PMID 18703711.
- ↑ ""questionable validity of results if words are presented out of context", Google Groups, August 29, 2008". Google. Retrieved 2013-07-10.
- ↑ March 29th, 2012 (2012-03-29). "Google Now Using ReCAPTCHA To Decode Street View Addresses". TechCrunch. Retrieved 2013-07-10.
- ↑ "Are you a robot? Introducing "No CAPTCHA reCAPTCHA"". Google. 2014-12-03. Retrieved 2015-04-14.
- ↑ "FAQ". reCAPTCHA.net.
- ↑ "reCAPTCHA: Stop Spam, Read Books". Google. Retrieved 2014-01-14.
- ↑ "Developer's Guide - reCAPTCHA — Google Developers". Google. Retrieved 2014-01-14.
- ↑ "Massachusetts woman's lawsuit accuses Google of using free labor to transcribe books, newspapers". Boston Business Journal.
- ↑ "BBC News - The evolution of those annoying online security tests". bbc.com. Retrieved 2014-09-22.
- ↑ "Captchas Are Becoming Ridiculous | Andrew Munsell". andrewmunsell.com. Retrieved 2014-09-22.
- ↑ http://www.forbes.com/sites/firewall/2010/06/18/those-scrambled-word-tests-for-stopping-spambots-are-tough-for-humans-too/
- ↑ "Strong CAPTCHA Guidelines" (PDF).
- ↑ "Google's reCAPTCHA busted by new attack".
- ↑ "Google's reCAPTCHA dented".
- ↑ "Def Con 18 Speakers". defcon.org.
- ↑ "Decoding reCAPTCHA Paper". Chad Houck.
- ↑ "Decoding reCAPTCHA Power Point". Chad Houck.
- 1 2 "Project Stiltwalker".
- ↑ Claudia Cruz-Perez; Oleg Starostenko; Fernando Uceda-Ponga; Vicente Alarcon-Aquino; Leobardo Reyes-Cabrera (30 June 2012). "Breaking reCAPTCHAs with Unpredictable Collapse: Heuristic Character Segmentation and Recognition". In Carrasco-Ochoa, Jesús Ariel; Martínez-Trinidad, José Francisco; Olvera López, José Arturo; Boyer, Kim L. Pattern Recognition. Lecture Notes in Computer Science. 7329. México. pp. 155–165. doi:10.1007/978-3-642-31149-9_16. ISBN 978-3-642-31148-2.
- ↑ "Screen Reader User Survey #4 Results".
- ↑ "Mailhide: Free Spam Protection". reCAPTCHA.net.
External links
| Wikimedia Commons has media related to ReCAPTCHA. |
- Official website
- Repository
- ReCAPTCHA: The job you didn't even know you had Two-page article in The Walrus magazine
- Luis; Maurer, Benjamin; McMillen, Colin; Abraham, David; Blum, Manuel (2008). "reCAPTCHA: Human-Based Character Recognition via Web Security Measures". Science. 321 (5895): 1465–1468. doi:10.1126/science.1160379. PMID 18703711.
- Massive-scale online collaboration, a TED talk by Luis von Ahn