Locality-sensitive hashing
Locality-sensitive hashing (LSH) reduces the dimensionality of high-dimensional data. LSH hashes input items so that similar items map to the same “buckets” with high probability (the number of buckets being much smaller than the universe of possible input items). LSH differs from conventional and cryptographic hash functions because it aims to maximize the probability of a “collision” for similar items.[1] Locality-sensitive hashing has much in common with data clustering and nearest neighbor search.
Hashing-based approximate nearest neighbor search algorithms generally use one of two main categories of hashing methods: either data-independent methods, such as locality-sensitive hashing (LSH); or data-dependent methods, such as Locality-preserving hashing (LPH).[2][3]
Definition
An LSH family[1][4][5] is defined for a metric space , a threshold and an approximation factor . This family is a family of functions which map elements from the metric space to a bucket . The LSH family satisfies the following conditions for any two points , using a function which is chosen uniformly at random:








- if , then (i.e.,p and q collide) with probability at least ,
- if , then with probability at most .





A family is interesting when . Such a family is called -sensitive.


Alternatively[6] it is defined with respect to a universe of items U that have a similarity function . An LSH scheme is a family of hash functions H coupled with a probability distribution D over the functions such that a function chosen according to D satisfies the property that for any .
![\phi : U \times U \to [0,1]](../I/m/a228b6b24f06dbfe99d030bfe60284d719e55541.svg)

![Pr_{h \in H} [h(a) = h(b)] = \phi(a,b)](../I/m/2682d7294bfd352e151fcabc2760e83a080791a9.svg)

Amplification
Given a -sensitive family , we can construct new families by either the AND-construction or OR-construction of .[1]


To create an AND-construction, we define a new family of hash functions g, where each function g is constructed from k random functions from . We then say that for a hash function , if and only if all for . Since the members of are independently chosen for any , is a -sensitive family.






To create an OR-construction, we define a new family of hash functions g, where each function g is constructed from k random functions from . We then say that for a hash function , if and only if for one or more values of i. Since the members of are independently chosen for any , is a -sensitive family.

Applications
LSH has been applied to several problem domains including
- Near-duplicate detection[7][8]
- Hierarchical clustering[9]
- Genome-wide association study[10]
- Image similarity identification
- Gene expression similarity identification
- Audio similarity identification
- Nearest neighbor search
- Audio fingerprint[11]
- Digital video fingerprinting
Methods
Bit sampling for Hamming distance
One of the easiest ways to construct an LSH family is by bit sampling.[5] This approach works for the Hamming distance over d-dimensional vectors . Here, the family of hash functions is simply the family of all the projections of points on one of the coordinates, i.e., , where is the th coordinate of . A random function from simply selects a random bit from the input point. This family has the following parameters: , .









Min-wise independent permutations
Suppose U is composed of subsets of some ground set of enumerable items S and the similarity function of interest is the Jaccard index J. If π is a permutation on the indices of S, for let . Each possible choice of π defines a single hash function h mapping input sets to elements of S.


Define the function family H to be the set of all such functions and let D be the uniform distribution. Given two sets the event that corresponds exactly to the event that the minimizer of π over lies inside . As h was chosen uniformly at random, and define an LSH scheme for the Jaccard index.




![Pr[h(A) = h(B)] = J(A,B)\,](../I/m/a54e5e0058c034a898dcbf92737b7db0feff4a15.svg)

Because the symmetric group on n elements has size n!, choosing a truly random permutation from the full symmetric group is infeasible for even moderately sized n. Because of this fact, there has been significant work on finding a family of permutations that is "min-wise independent" - a permutation family for which each element of the domain has equal probability of being the minimum under a randomly chosen π. It has been established that a min-wise independent family of permutations is at least of size .[12] and that this bound is tight.[13]

Because min-wise independent families are too big for practical applications, two variant notions of min-wise independence are introduced: restricted min-wise independent permutations families, and approximate min-wise independent families. Restricted min-wise independence is the min-wise independence property restricted to certain sets of cardinality at most k.[14] Approximate min-wise independence differs from the property by at most a fixed ε.[15]
Open source methods
Nilsimsa Hash
Nilsimsa is an anti-spam focused locality-sensitive hashing algorithm.[16] The goal of Nilsimsa is to generate a hash digest of an email message such that the digests of two similar messages are similar to each other. The paper suggests that the Nilsimsa satisfies three requirements:
- The digest identifying each message should not vary significantly for changes that can be produced automatically.
- The encoding must be robust against intentional attacks.
- The encoding should support an extremely low risk of false positives.
TLSH
TLSH is locality-sensitive hashing algorithm designed for a range of security and digital forensic applications.[17] The goal of TLSH is to generate a hash digest of document such that if two digests have a low distance between them, then it is likely that the messages are similar to each other.
Testing performed in the paper demonstrates that on a range of file types identified the Nilsimsa hash as having a significantly higher false positive rate when compared to other similarity digest schemes such as TLSH, Ssdeep and Sdhash.
An implementation of TLSH is available as open-source software.[18]
Random projection
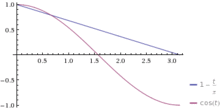


The random projection method of LSH due to Moses Charikar[6] called SimHash (also sometimes called arccos[19]) is designed to approximate the cosine distance between vectors. The basic idea of this technique is to choose a random hyperplane (defined by a normal unit vector r) at the outset and use the hyperplane to hash input vectors.
Given an input vector v and a hyperplane defined by r, we let . That is, depending on which side of the hyperplane v lies.


Each possible choice of r defines a single function. Let H be the set of all such functions and let D be the uniform distribution once again. It is not difficult to prove that, for two vectors , , where is the angle between u and v. is closely related to .

![Pr[h(u) = h(v)] = 1 - \frac{\theta(u,v)}{\pi}](../I/m/a272a670ff9964c606250aa9bdfc8b6814e72853.svg)



In this instance hashing produces only a single bit. Two vectors' bits match with probability proportional to the cosine of the angle between them.
Stable distributions
The hash function [20] maps a d dimensional vector onto a set of integers. Each hash function in the family is indexed by a choice of random and where is a d dimensional vector with entries chosen independently from a stable distribution and is a real number chosen uniformly from the range [0,r]. For a fixed the hash function is given by .







Other construction methods for hash functions have been proposed to better fit the data. [21] In particular k-means hash functions are better in practice than projection-based hash functions, but without any theoretical guarantee.
LSH algorithm for nearest neighbor search
One of the main applications of LSH is to provide a method for efficient approximate nearest neighbor search algorithms. Consider an LSH family . The algorithm has two main parameters: the width parameter k and the number of hash tables L.
In the first step, we define a new family of hash functions g, where each function g is obtained by concatenating k functions from , i.e., . In other words, a random hash function g is obtained by concatenating k randomly chosen hash functions from . The algorithm then constructs L hash tables, each corresponding to a different randomly chosen hash function g.
![g(p) = [h_1(p), ..., h_k(p)]](../I/m/666ecff3b981120e3b1bc766187d13b711c521a2.svg)
In the preprocessing step we hash all n points from the data set S into each of the L hash tables. Given that the resulting hash tables have only n non-zero entries, one can reduce the amount of memory used per each hash table to using standard hash functions.

Given a query point q, the algorithm iterates over the L hash functions g. For each g considered, it retrieves the data points that are hashed into the same bucket as q. The process is stopped as soon as a point within distance from q is found.

Given the parameters k and L, the algorithm has the following performance guarantees:
- preprocessing time: , where t is the time to evaluate a function on an input point p;
- space: , plus the space for storing data points;
- query time: ;
- the algorithm succeeds in finding a point within distance from q (if there exists a point within distance R) with probability at least ;




For a fixed approximation ratio and probabilities and , one can set and , where . Then one obtains the following performance guarantees:




- preprocessing time: ;
- space: , plus the space for storing data points;
- query time: ;



See also
- Bloom Filter
- Curse of dimensionality
- Feature hashing
- Fourier-related transforms
- Multilinear subspace learning
- Principal component analysis
- Random indexing[22]
- Rolling hash
- Singular value decomposition
- Sparse distributed memory
- Wavelet compression
References
- 1 2 3 Rajaraman, A.; Ullman, J. (2010). "Mining of Massive Datasets, Ch. 3.".
- ↑ Zhao, Kang; Lu, Hongtao; Mei, Jincheng (2014). "Locality Preserving Hashing". pp. 2874–2880.
- ↑ Tsai, Yi-Hsuan; Yang, Ming-Hsuan (October 2014). "Locality preserving hashing". pp. 2988–2992. doi:10.1109/ICIP.2014.7025604. ISSN 1522-4880.
- ↑ Gionis, A.; Indyk, P.; Motwani, R. (1999). "Similarity Search in High Dimensions via Hashing". Proceedings of the 25th Very Large Database (VLDB) Conference.
- 1 2 Indyk, Piotr.; Motwani, Rajeev. (1998). "Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality.". Proceedings of 30th Symposium on Theory of Computing.
- 1 2 Charikar, Moses S. (2002). "Similarity Estimation Techniques from Rounding Algorithms". Proceedings of the 34th Annual ACM Symposium on Theory of Computing. pp. 380–388. doi:10.1145/509907.509965.
- ↑ Gurmeet Singh, Manku; Jain, Arvind; Das Sarma, Anish (2007), "Detecting near-duplicates for web crawling", Proceedings of the 16th international conference on World Wide Web, ACM.
- ↑ Das, Abhinandan S.; et al. (2007), "Google news personalization: scalable online collaborative filtering", Proceedings of the 16th international conference on World Wide Web, ACM, doi:10.1145/1242572.1242610.
- ↑ Koga, Hisashi, Tetsuo Ishibashi, and Toshinori Watanabe (2007), "Fast agglomerative hierarchical clustering algorithm using Locality-Sensitive Hashing", Knowledge and Information Systems, 12 (1): 25–53, doi:10.1007/s10115-006-0027-5.
- ↑ Brinza, Dumitru; et al. (2010), "RAPID detection of gene–gene interactions in genome-wide association studies", Bioinformatics, 26 (22): 2856–2862, doi:10.1093/bioinformatics/btq529
- ↑ dejavu - Audio fingerprinting and recognition in Python
- ↑ Broder, A.Z.; Charikar, M.; Frieze, A.M.; Mitzenmacher, M. (1998). "Min-wise independent permutations". Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing. pp. 327–336. doi:10.1145/276698.276781. Retrieved 2007-11-14.
- ↑ Takei, Y.; Itoh, T.; Shinozaki, T. "An optimal construction of exactly min-wise independent permutations". Technical Report COMP98-62, IEICE, 1998.
- ↑ Matoušek, J.; Stojakovic, M. (2002). "On Restricted Min-Wise Independence of Permutations". Preprint. Retrieved 2007-11-14.
- ↑ Saks, M.; Srinivasan, A.; Zhou, S.; Zuckerman, D. (2000). "Low discrepancy sets yield approximate min-wise independent permutation families". Information Processing Letters. 73 (1-2): 29–32. doi:10.1016/S0020-0190(99)00163-5. Retrieved 2007-11-14.
- ↑ Damiani et. al (2004). "An Open Digest-based Technique for Spam Detection" (PDF). Retrieved 2013-09-01.
- ↑ Oliver et. al (2013). "TLSH - A Locality Sensitive Hash". 4th Cybercrime and Trustworthy Computing Workshop. Retrieved 2015-04-06.
- ↑ "TLSH". Retrieved 2014-04-10.
- ↑ Alexandr Andoni; Indyk, P. (2008). "Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions". Communications of the ACM. 51 (1): 117–122. doi:10.1145/1327452.1327494.
- ↑ Datar, M.; Immorlica, N.; Indyk, P.; Mirrokni, V.S. (2004). "Locality-Sensitive Hashing Scheme Based on p-Stable Distributions". Proceedings of the Symposium on Computational Geometry.
- ↑ Pauleve, L.; Jegou, H.; Amsaleg, L. (2010). "Locality sensitive hashing: A comparison of hash function types and querying mechanisms". Pattern recognition Letters.
- ↑ Gorman, James, and James R. Curran. "Scaling distributional similarity to large corpora." Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2006.
Further reading
- Samet, H. (2006) Foundations of Multidimensional and Metric Data Structures. Morgan Kaufmann. ISBN 0-12-369446-9
External links
- Alex Andoni's LSH homepage
- LSHKIT: A C++ Locality Sensitive Hashing Library
- A Python Locality Sensitive Hashing library that optionally supports persistence via redis
- Caltech Large Scale Image Search Toolbox: a Matlab toolbox implementing several LSH hash functions, in addition to Kd-Trees, Hierarchical K-Means, and Inverted File search algorithms.
- Slash: A C++ LSH library, implementing Spherical LSH by Terasawa, K., Tanaka, Y
- LSHBOX: An Open Source C++ Toolbox of Locality-Sensitive Hashing for Large Scale Image Retrieval, Also Support Python and MATLAB.
- SRS: A C++ Implementation of An In-memory, Space-efficient Approximate Nearest Neighbor Query Processing Algorithm based on p-stable Random Projection
- JavaScript port of TLSH (Trend Micro Locality Sensitive Hashing) bundled as node.js module