Cancer genome sequencing
Cancer genome sequencing is the whole genome sequencing of a single, homogeneous or heterogeneous group of cancer cells. It is a biochemical laboratory method for the characterization and identification of the DNA or RNA sequences of cancer cell(s).
Unlike whole genome (WG) sequencing which is typically from blood cells, such as J. Craig Venter's [1] and James D. Watson’s WG sequencing projects,[2] saliva, epithelial cells or bone - cancer genome sequencing involves direct sequencing of primary tumor tissue, adjacent or distal normal tissue, the tumor micro environment such as fibroblast/stromal cells, or metastatic tumor sites.
Similar to whole genome sequencing, the information generated from this technique include: identification of nucleotide bases (DNA or RNA), copy number and sequence variants, mutation status, and structural changes such as chromosomal translocations and fusion genes.
Cancer genome sequencing is not limited to WG sequencing and can also include exome, transcriptome, micronome sequencing, and end-sequence profiling. These methods can be used to quantify gene expression, miRNA expression, and identify alternative splicing events in addition to sequence data.
The first report of cancer genome sequencing appeared in 2006. In this study 13,023 genes were sequenced in 11 breast and 11 colorectal tumors.[3] A subsequent follow up was published in 2007 where the same group added just over 5,000 more genes and almost 8,000 transcript species to complete the exomes of 11 breast and colorectal tumors.[4] A cancer genome to be sequenced was from cytogenetically normal acute myeloid leukaemia by Ley et al. in November 2008.[5] The first breast cancer tumor was sequenced by Shah et al. in October 2009,[6] the first lung and skin tumors by Pleasance et al. in January 2010,[7][8] and the first prostate tumors by Berger et al. in February 2011.[9]
History
Historically, cancer genome sequencing efforts has been divided between transcriptome-based sequencing projects and DNA-centered efforts.
The Cancer Genome Anatomy Project (CGAP) was first funded in 1997[10] with the goal of documenting the sequences of RNA transcripts in tumor cells.[11] As technology improved, the CGAP expanded its goals to include the determination of gene expression profiles of cancerous, precancerous and normal tissues.[12]
The CGAP published the largest publicly available collection of cancer expressed sequence tags in 2003.[13]
The Sanger Institute's Cancer Genome Project, first funded in 2005, focuses on DNA sequencing. It has published a census of genes causally implicated in cancer,[14] and a number of whole-genome resequencing screens for genes implicated in cancer.[15]
The International Cancer Genome Consortium (ICGC) was founded in 2007 with the goal of integrating available genomic, transcriptomic and epigenetic data from many different research groups.[16][17] As of December 2011, the ICGC includes 45 committed projects and has data from 2,961 cancer genomes available.[16]
Societal Impact
The Complexity and Biology of Cancer
The process of tumorigenesis that transforms a normal cell to a cancerous cell involve a series of complex genetic and epigenetic changes.[18][19][20] Identification and characterization of all these changes can be accomplished through various cancer genome sequencing strategies.
The power of cancer genome sequencing lies in the heterogeneity of cancers and patients. Most cancers have a variety of subtypes and combined with these ‘cancer variants’ are the differences between a cancer subtype in one individual and in another individual. Cancer genome sequencing allows clinicians and oncologists to identify the specific and unique changes a patient has undergone to develop their cancer. Based on these changes, a personalized therapeutic strategy can be undertaken.[21][22]
Clinical Relevance

A big contribution to cancer death and failed cancer treatment is clonal evolution at the cytogenetic level, for example as seen in acute myeloid leukaemia (AML).[23][24] In a Nature study published in 2011, Ding et al. identified cellular fractions characterized by common mutational changes to illustrate the heterogeneity of a particular tumor pre- and post-treatment vs. normal blood in one individual.[25]
These cellular factions could only have been identified through cancer genome sequencing, showing the information that sequencing can yield, and the complexity and heterogeneity of a tumor within one individual.
Comprehensive Cancer Genomic Projects
The two main projects focused on complete cancer characterization in individuals, heavily involving sequencing include the Cancer Genome Project, based at the Wellcome Trust Sanger Institute and the Cancer Genome Atlas funded by the National Cancer Institute (NCI) and the National Human Genome Research Institute (NHGRI). Combined with these efforts, the International Cancer Genome Consortium (a larger organization) is a voluntary scientific organization that provides a forum for collaboration among the world's leading cancer and genomic researchers.
Cancer Genome Project (CGP)
The Cancer Genome Projects goal is to identify sequence variants and mutations critical in the development of human cancers. The project involves the systematic screening of coding genes and flanking splice junctions of all genes in the human genome for acquired mutations in human cancers. To investigate these events, the discovery sample set will include DNA from primary tumor, normal tissue (from the same individuals) and cancer cell lines. All results from this project are amalgamated and stored within the COSMIC cancer database. COSMIC also includes mutational data published in scientific literature.
The Cancer Genome Atlas (TCGA)
The TCGA is multi-institutional effort to understand the molecular basis of cancer through genome analysis technologies, including large-scale genome sequencing techniques. Hundreds of samples are being collected, sequenced and analyzed. Currently the cancer tissue being collected include: central nervous system, breast, gastrointestinal, gynecologic, head and neck, hematologic, thoracic, and urologic.
The components of the TCGA research network include: Biospecimen Core Resources, Genome Characterization Centers, Genome Sequencing Centers, Proteome Characterization Centers, a Data Coordinating Center, and Genome Data Analysis Centers. Each cancer type will undergo comprehensive genomic characterization and analysis. The data and information generated is freely available through the projects TCGA data portal.
International Cancer Genome Consortium (ICGC)
The ICGC’s goal is “To obtain a comprehensive description of genomic, transcriptomic and epigenomic changes in 50 different tumor types and/or subtypes which are of clinical and societal importance across the globe”.[16]
Technologies and platforms


Cancer genome sequencing utilizes the same technology involved in whole genome sequencing. The history of sequencing has come a long way, originating in 1977 by two independent groups - Fredrick Sanger’s enzymatic didoxy DNA sequencing technique [26] and the Allen Maxam and Walter Gilbert chemical degradation technique.[27] Following these landmark papers, over 20 years later ‘Second Generation’ high-throughput next generation sequencing (HT-NGS) was born followed by ‘Third Generation HT-NGS technology’ in 2010.[28] The figures to the right illustrate the general biological pipeline and companies involved in second and third generation HT-NGS sequencing.
Three major second generation platforms include Roche/454 Pyro-sequencing, ABI/SOLiD sequencing by ligation, and Illumina’s bridge amplification sequencing technology. Three major third generation platforms include Pacific Biosciences Single Molecule Real Time (SMRT) sequencing, Oxford Nanopore sequencing, and Ion semiconductor sequencing.
Data Analysis
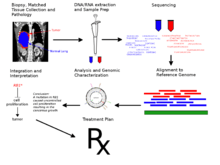
As with any genome sequencing project, the reads must be assembled to form a representation of the chromosomes being sequenced. With cancer genomes, this is usually done by aligning the reads to the human reference genome.
Since even non-cancerous cells accumulate somatic mutations, it is necessary to compare sequence of the tumor to a matched normal tissue in order to discover which mutations are unique to the cancer. In some cancers, such as leukemia, it is not practical to match the cancer sample to a normal tissue, so a different non-cancerous tissue must be used.[25]
It has been estimated that discovery of all somatic mutations in a tumor would require 30-fold sequencing coverage of the tumor genome and a matched normal tissue.[29] By comparison, the original draft of the human genome had approximately 65-fold coverage.[30]
A major goal of cancer genome sequencing is to identify driver mutations: genetic changes which increase the mutation rate in the cell, leading to more rapid tumor evolution and metastasis.[31] It is difficult to determine driver mutations from DNA sequence alone; but drivers tend to be the most commonly shared mutations amongst tumors, cluster around known oncogenes, and are tend to be non-silent.[29] Passenger mutations, which are not important in the progression of the disease, are randomly distributed throughout the genome. It has been estimated that the average tumor carries c.a. 80 somatic mutations, fewer than 15 of which are expected to be drivers.[32]
A personal-genomics analysis requires further functional characterization of the detected mutant genes, and the development of a basic model of the origin and progression of the tumor. This analysis can be used to make pharmacological treatment recommendations.[21][22] As of February 2012, this has only been done for patients clinical trials designed to assess the personal genomics approach to cancer treatment.[22]
Limitations
A large-scale screen for somatic mutations in breast and colorectal tumors showed that many low-frequency mutations each make small contribution to cell survival.[32] If cell survival is determined by many mutations of small effect, it is unlikely that genome sequencing will uncover a single "Achilles heel" target for anti-cancer drugs. However, somatic mutations tend to cluster in a limited number of signalling pathways,[29][32][33] which are potential treatment targets.
Cancers are heterogeneous populations of cells. When sequence data is derived from a whole tumor, information about the differences in sequence and expression pattern between cells is lost.[34] This difficulty can be ameliorated by single-cell analysis.
Clinically significant properties of tumors, including drug resistance, are sometimes caused by large-scale rearrangements of the genome, rather than single mutations.[35] In this case, information about single nucleotide variants will be of limited utility.[34]
Cancer genome sequencing can be used to provide clinically relevant information in patients with rare or novel tumor types. Translating sequence information into a clinical treatment plan is highly complicated, requires experts of many different fields, and is not guaranteed to lead to an effective treatment plan.[21][22]
Incidentalome
The incidentalome is the set of detected genomic variants not related to the cancer under study.[36] (The term is a play on the name incidentaloma, which designates tumors and growths detected on whole-body imaging by coincidence).[37] The detection of such variants may result in additional measures such as further testing or lifestyle management.[36]
See also
- 454 Life Sciences Pyrosequencing
- ABI Solid Sequencing
- Cancer Genome Project
- Cancer Genome Atlas
- DNA nanoball sequencing
- International Cancer Genome Consortium
- Ion semiconductor sequencing
- Nanopore sequencing
- Next-generation sequencing
- Oncogenomics
- Polony sequencing
- Pyrosequencing
- Single molecule real time sequencing
References
- ↑ Samuel Levy; et al. (October 2007). "The Diploid Genome Sequence of an Individual Human". PLoS Biology. 5 (10): e254. doi:10.1371/journal.pbio.0050254. PMC 1964779
 . PMID 17803354.
. PMID 17803354. - ↑ David A. Wheeler; et al. (April 2008). "The complete genome of an individual by massively parallel DNA sequencing". Nature. 452 (7189): 872–6. doi:10.1038/nature06884. PMID 18421352.
- ↑ Sjoblom, T.; Jones, S.; Wood, L. D.; Parsons, D. W.; Lin, J.; Barber, T. D.; Mandelker, D.; Leary, R. J.; Ptak, J.; Silliman, N.; Szabo, S.; Buckhaults, P.; Farrell, C.; Meeh, P.; Markowitz, S. D.; Willis, J.; Dawson, D.; Willson, J. K. V.; Gazdar, A. F.; Hartigan, J.; Wu, L.; Liu, C.; Parmigiani, G.; Park, B. H.; Bachman, K. E.; Papadopoulos, N.; Vogelstein, B.; Kinzler, K. W.; Velculescu, V. E. (2006). "The Consensus Coding Sequences of Human Breast and Colorectal Cancers". Science. 314 (5797): 268–274. doi:10.1126/science.1133427. ISSN 0036-8075. PMID 16959974.
- ↑ Wood, L. D.; Parsons, D. W.; Jones, S.; Lin, J.; Sjoblom, T.; Leary, R. J.; Shen, D.; Boca, S. M.; Barber, T.; Ptak, J.; Silliman, N.; Szabo, S.; Dezso, Z.; Ustyanksky, V.; Nikolskaya, T.; Nikolsky, Y.; Karchin, R.; Wilson, P. A.; Kaminker, J. S.; Zhang, Z.; Croshaw, R.; Willis, J.; Dawson, D.; Shipitsin, M.; Willson, J. K. V.; Sukumar, S.; Polyak, K.; Park, B. H.; Pethiyagoda, C. L.; Pant, P. V. K.; Ballinger, D. G.; Sparks, A. B.; Hartigan, J.; Smith, D. R.; Suh, E.; Papadopoulos, N.; Buckhaults, P.; Markowitz, S. D.; Parmigiani, G.; Kinzler, K. W.; Velculescu, V. E.; Vogelstein, B. (2007). "The Genomic Landscapes of Human Breast and Colorectal Cancers". Science. 318 (5853): 1108–1113. doi:10.1126/science.1145720. ISSN 0036-8075. PMID 17932254.
- ↑ Timothy Ley; et al. (November 2008). "DNA sequencing of a cytogenetically normal acute myeloid leukaemia genome". Nature. 456 (7218): 66–72. doi:10.1038/nature07485. PMC 2603574. PMID 18987736.
- ↑ Sohrab P. Shah; et al. (October 2009). "Mutational evolution in a lobular breast tumour profiled at single nucleotide resolution". Nature. 461 (7265). doi:10.1038/nature08489. PMID 19812674.
- ↑ Erin D. Pleasance; et al. (December 2009). "A small-cell lung cancer genome with complex signatures of tobacco exposure". Nature. 463 (7278). doi:10.1038/nature08629. PMC 2880489. PMID 20016488.
- ↑ Erin D. Pleasance; et al. (December 2009). "A comprehensive catalogue of somatic mutations from a human cancer genome". Nature. 463 (7278). doi:10.1038/nature08658. PMC 3145108. PMID 20016485.
- ↑ Michael F. Berger; et al. (February 2011). "The genomic complexity of primary human prostate cancer". Nature. 470 (7333). doi:10.1038/nature09744. PMC 3075885. PMID 21307934.
- ↑ E Pinnisi (May 1997). "A catalog of cancer genes at the click of a mouse". Science. 267 (5315): 1023–4. doi:10.1126/science.276.5315.1023. PMID 9173535.
- ↑ B Kuska (December 1996). "Cancer genome anatomy project set for takeoff". Journal of the National Cancer Institute. 88 (24): 1801–3. PMID 8961968.
- ↑ "Cancer Genome Anatomy Project (CGAP) | Cancer Genome Characterization Initiative (CGCI)". Cgap.nci.nih.gov. Retrieved 2013-09-14.
- ↑ Archived May 3, 2011, at the Wayback Machine.
- ↑ "COSMIC: Cancer Gene census". Sanger.ac.uk. Archived from the original on July 2, 2013. Retrieved 2013-09-14.
- ↑ www-core (Web team) (2013-01-30). "Cancer genome project (CGP) - Wellcome Trust Sanger Institute". Sanger.ac.uk. Archived from the original on July 2, 2013. Retrieved 2013-09-14.
- 1 2 3 "International Cancer Genome Consortium". Icgc.org. Retrieved 2013-09-14.
- ↑ International Cancer Genome Consortium (April 2010). "International network of cancer genome projects". Nature. 464 (7291): 993–8. doi:10.1038/nature08987. PMC 2902243. PMID 20393554.
- ↑ Kenneth W Kinzler; et al. (October 1996). "Lessons from Hereditary Colorectal Cancer". Cell. 87 (2). doi:10.1016/S0092-8674(00)81333-1. PMID 8861899.
- ↑ Peter A. Jones; et al. (February 2007). "The Epigenomics of Cancer". Cell. 128 (4). doi:10.1016/j.cell.2007.01.029. PMID 17320506.
- ↑ Angela H. Ting; et al. (December 2006). "The cancer epigenome--components and functional correlates". Genes & Development. 20 (23). doi:10.1101/gad.1464906. PMID 17158741.
- 1 2 3 Jone, S.J.; et al. (2010). "Evolution of an adenocarcinoma in response to selection by targeted kinase inhibitors.". Genome Biology. 11 (8): R82. doi:10.1186/gb-2010-11-8-r82. PMC 2945784. PMID 20696054.
- 1 2 3 4 Roychowdhury, S.; et al. (November 2011). "Personalized oncology through integrative high-throughput sequencing: a pilot study". Science Translational Medicine. 3 (111). doi:10.1126/scitranslmed.3003161. PMID 22133722.
- ↑ Joseph R. Testa; et al. (September 1979). "Evolution of Karyotypes in Acute Nonlymphocytic Leukemia". Cancer Research. 39 (9): 3619–27. PMID 476688.
- ↑ Garson OM; et al. (July 1989). "Cytogenetic studies of 103 patients with acute myelogenous leukemia in relapse". Cancer Genetics and Cytogenetics. 40 (2): 187–202. PMID 2766243.
- 1 2 Ding, L.; et al. (January 2012). "Clonal evolution in relapsed acute myeloid leukaemia revealed by whole-genome sequencing". Nature. 481 (7382). doi:10.1038/nature10738. PMID 22237025.
- ↑ Frederick Sanger; et al. (December 1977). "DNA sequencing with chain-terminating inhibitors". PNAS. 74 (12): 104–8. PMID 1422003.
- ↑ Allan Maxam; Walter Gilbert (February 1977). "A new method for sequencing DNA". PNAS. 74 (2): 560–4. doi:10.1073/pnas.74.2.560. PMC 392330. PMID 265521.
- ↑ Chandra Shekhar Pareek; et al. (November 2011). "Sequencing technologies and genome sequencing". Journal of Applied Genetics. 52 (4). doi:10.1007/s13353-011-0057-x. PMC 3189340. PMID 21698376.
- 1 2 3 Straton, M. R.; Campbell, P. J.; Futreal, P.A. (April 2009). "The cancer genome". Nature. 458 (7239). doi:10.1038/nature07943.
- ↑ Lander, E.S.; et al. (February 2001). "Initial sequencing and analysis of the human genome". Nature. 409 (6822). doi:10.1038/35057062. PMID 11237011.
- ↑ Wong, K. M.; Hudson, T. J.; McPherson, J. D. (September 2011). "Unraveling the genetics of cancer: genome sequencing and beyond". Annual Review of Genomics and Human Genetics. 12: 407–30. doi:10.1146/annurev-genom-082509-141532. PMID 21639794.
- 1 2 3 Wood, L.D.; et al. (November 2007). "The genomic landscapes of human breast and colorectal cancers". Science. 318 (5853): 8–9. doi:10.1126/science.1145720. PMID 17932254.
- ↑ Jones, S.; et al. (September 2008). "Core signaling pathways in human pancreatic cancers revealed by global genomic analyses". Science. 321 (5897). doi:10.1126/science.1164368. PMC 2848990. PMID 18772397.
- 1 2 Miklos, G. L. (May 2005). "The human cancer genome project: one more misstep in the war on cancer". Nature Biotechnology. 23 (5): 535–7. doi:10.1038/nbt0505-535. PMID 15877064.
- ↑ Duesberg, P.; Rasnick, D. (2004). "Aneuploidy approaching a perfect score in predicting and preventing cancer: highlights from a conference held in Oakland, CA in January, 2004.". Cell Cycle. 3 (6): 823–8. PMID 15197343.
- 1 2 Kohane, I. S.; Masys, D. R.; Altman, R. B. (2006). "The Incidentalome: A Threat to Genomic Medicine". JAMA. 296 (2): 212–215. doi:10.1001/jama.296.2.212. PMID 16835427.
- ↑ Cancer Gene Sequencing Raises New Medical Ethics Issues by Janis C. Kelly. Sep 06, 2013
External links
- The Cancer Genome Project
- CGAP
- The Cancer Genome Atlas
- Cancer Genome Project
- Cancer Genome Project
- International Cancer Genome Consortium
- Francis S. Collins and Anna D. Barker. "Mapping the Cancer Genome". Scientific American, February 2007
- Circulating Tumor DNA Sequencing